#FastDFS源码解析(1)--------源码目录介绍
概念:
FastDFS是余庆(前阿里巴巴架构师,现易到用车架构师)开发的一个开源的轻量级分布式文件系统,对于小文件的存储性能特别高,适合以文件为载体的在线服务。应用场景不再赘述,网上相关资料不少。然而在很多家大公司明里暗里都使用了FastDFS以后,居然对他代码的分析文章这么少。本人才疏学浅,且尝试着分析一翻,如果分析的不好,诚心求教。
开始:
源码在sourceforge,github上都能找到。这里我使用的FastDFS v5.01版本,值得注意的是,这个版本干掉了该死了libevent,直接使用epoll,kqueue,可读性提高了不少,而且0依赖了,赞一个。
源码目录包括了common,test,client,stroage,tracker
按文件夹顺序和首字母进行分析:
common文件夹:
common_define.h:
跳过首字母a的文件先介绍这个,是因为这个文件定义了整个系统的一些环境变量,包括bool类型,全局变量等等。下文中你没见过,我也没提的变量或者宏都取自这里。
avl_tree.c/avl_tree.h:
对于avl树的定义和实现,这是FastDFS实现trunk功能和单盘恢复功能所依赖的数据结构
1 2 3 4 5 6 7 8 9 10 11 12 typedef struct tagAVLTreeNode { void *data; struct tagAVLTreeNode *left ; struct tagAVLTreeNode *right ; byte balance; } AVLTreeNode; typedef struct tagAVLTreeInfo { AVLTreeNode *root; FreeDataFunc free_data_func; CompareFunc compare_func; } AVLTreeInfo;
经典的数据结构,没有修改的原汁原味。
base64.c/base64.h:
FastDFS得到文件包含的信息后,用base64算法对其编码生成文件ID。
chain.c/chain.hi:
对于链表的实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 typedef struct tagChainNode { void *data; struct tagChainNode *next ; } ChainNode; typedef struct { int type; ChainNode *head; ChainNode *tail; FreeDataFunc freeDataFunc; CompareFunc compareFunc; } ChainList;
type变量是定义链表的使用方式的:
CHAIN_TYPE_INSERT: insert new node before head
CHAIN_TYPE_APPEND: insert new node after tail
CHAIN_TYPE_SORTED: sorted chain
在fast_mblock中#include了它,但是并没有使用,直接注释了这个include也成功编译无报错,可能后续会使用吧?这里会和鱼大咨询下。mark。
connect_pool.c/connect_pool.h:
连接池的定义与实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 typedef struct { int sock; int port; char ip_addr[IP_ADDRESS_SIZE]; } ConnectionInfo; struct tagConnectionManager ;typedef struct tagConnectionNode { ConnectionInfo *conn; struct tagConnectionManager *manager ; struct tagConnectionNode *next ; time_t atime; } ConnectionNode; typedef struct tagConnectionManager { ConnectionNode *head; int total_count; int free_count; pthread_mutex_t lock; } ConnectionManager; typedef struct tagConnectionPool { HashArray hash_array; pthread_mutex_t lock; int connect_timeout; int max_count_per_entry; int max_idle_time; } ConnectionPool;
呃,注释已经一目了然了。
三层结构
pool->manager->node
pool使用哈希来定位manager,因为作为key的ip:port是唯一的,而后用链表来管理该节点的所有连接。
fast_mblock.c/fast_mblock.h:
链表的一个变种,存储有已分配的对象和已经释放的对象,大致相当于一个对象池,在trunk功能中被使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 struct fast_mblock_node { struct fast_mblock_node *next ; char data[0 ]; }; struct fast_mblock_malloc { struct fast_mblock_malloc *next ; }; struct fast_mblock_man { struct fast_mblock_node *free_chain_head ; struct fast_mblock_malloc *malloc_chain_head ; int element_size; int alloc_elements_once; pthread_mutex_t lock; };
fast_task_queue.c/fast_task_queue.h:
任务队列,挺重要的一个数据结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 typedef struct ioevent_entry { int fd; FastTimerEntry timer; IOEventCallback callback; } IOEventEntry; struct nio_thread_data { struct ioevent_puller ev_puller ; struct fast_timer timer ; int pipe_fds[2 ]; struct fast_task_info *deleted_list ; }; struct fast_task_info { IOEventEntry event; char client_ip[IP_ADDRESS_SIZE]; void *arg; char *data; int size; int length; int offset; int req_count; TaskFinishCallBack finish_callback; struct nio_thread_data *thread_data ; struct fast_task_info *next ; }; struct fast_task_queue { struct fast_task_info *head ; struct fast_task_info *tail ; pthread_mutex_t lock; int max_connections; int min_buff_size; int max_buff_size; int arg_size; bool malloc_whole_block; };
fast_timer.c/fast_timer.h:
时间哈希表,以unix时间戳作为key,用双向链表解决冲突,可以根据当前的使用量进行rehash等操作。
在刚才的fast_task_queue中被使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 typedef struct fast_timer_entry { int64_t expires; void *data; struct fast_timer_entry *prev ; struct fast_timer_entry *next ; bool rehash; } FastTimerEntry; typedef struct fast_timer_slot { struct fast_timer_entry head ; } FastTimerSlot; typedef struct fast_timer { int slot_count; int64_t base_time; int64_t current_time; FastTimerSlot *slots; } FastTimer;
fdfs_global.c/fdfs_global.h:
定义了fdfs系统所使用的全局变量,包括超时,版本号等等
1 2 3 4 5 6 7 int g_fdfs_connect_timeout = DEFAULT_CONNECT_TIMEOUT;int g_fdfs_network_timeout = DEFAULT_NETWORK_TIMEOUT;char g_fdfs_base_path[MAX_PATH_SIZE] = {'/' , 't' , 'm' , 'p' , '\0' };Version g_fdfs_version = {5 , 1 }; bool g_use_connection_pool = false ;ConnectionPool g_connection_pool; int g_connection_pool_max_idle_time = 3600 ;
fdfs_http_shared.c/fdfs_http_share.h:
FastDFS使用token来防盗链和分享图片,这一段我也不确定。回头再来看。
hash.c/hash.h:
经典的哈希结构,在FastDFS中应用的很广
哈希找到域,而后用链表解决冲突 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 typedef struct tagHashData { int key_len; int value_len; int malloc_value_size; #ifdef HASH_STORE_HASH_CODE unsigned int hash_code; #endif char *value; struct tagHashData *next ; char key[0 ]; } HashData; typedef struct tagHashArray { HashData **buckets; HashFunc hash_func; int item_count; unsigned int *capacity; double load_factor; int64_t max_bytes; int64_t bytes_used; bool is_malloc_capacity; bool is_malloc_value; unsigned int lock_count; pthread_mutex_t *locks; } HashArray; typedef struct tagHashStat //所有hash 的统计情况{ unsigned int capacity; int item_count; int bucket_used; double bucket_avg_length; int bucket_max_length; } HashStat;
http_func.c/http_func.h:
http功能已经被砍掉了,这个也回头来看。
ini_file_reader.c/ini_file_reader.h:
FastDFS用于初始化加载配置文件的函数。
ioevent.c/ioevent.h && ioevent_loop.c/ioevent_loop.h:
对epoll,kqueue进行简单封装,成为一个有时间和网络的事件库。这部分逻辑应该会开独立的一章来分析
linux_stack_trace.c/linux_stack_trace.h:
这个模块是在程序段错误后输出栈跟踪信息,呃似乎不是鱼大写的
local_ip_func.c/local_ip_func.h:
基于系统调用getifaddrs来获取本地IP
logger.c/logger.h:
这个太明显了,log模块
md5.c/md5.h:
fdfs_http_shared.c中被调用,在fdfs_http_gen_token的方法中对secret_key,file_id,timestamp进行md5得到token
mime_file_parser.c/mime_file_parser.h:
从配置文件中加载mime识别的配置,至于什么是mime。。我也不知道,我问问大神们看看。
**_os_bits.h:**
定义了OS的位数
process_ctrl.c/process_ctrl.h:
从配置文件中载入pid路径,定义了pid文件的增删查改,并且提供了进程停止,重启等方法
pthread_func.c/pthread_func.h:
线程相关的操作,包括初始化,创建,杀死线程
sched_thread.c/sched_thread.h:
定时任务线程的模块,按照hour:minute的期限执行任务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 typedef struct tagScheduleEntry { int id; TimeInfo time_base; int interval; TaskFunc task_func; void *func_args; time_t next_call_time; struct tagScheduleEntry *next ; } ScheduleEntry; typedef struct { ScheduleEntry *entries; int count; } ScheduleArray; typedef struct { ScheduleArray scheduleArray; ScheduleEntry *head; ScheduleEntry *tail; bool *pcontinue_flag; } ScheduleContext;
稍微看了下实现的算法,这是一个变种的链表,实现了一个变种的队列。
但是所有的数据都存在scheduleArray这个数组里面,每次新任务插入后,会对数组按时间进行一次排序
这样可以保证头指针的是最先需要执行的。
而后每次对head进行出队,初始化next域以后重新从tail入队。
总体来看是非常的简单高效的。
shared_func.c/shared_func.h:
一些工具函数,比如设置随机种子什么的,没必要单独开个文件,所以放在一起了。
sockopt.c/sockopt.h:
socket的一些工具函数,进行了简单的封装。
tracker文件夹:
先分析tracker是因为tracker只集成了网络部分,而storage还有处理磁盘吞吐的,相对复杂一些
fdfs_share_func.c/fdfs_share_func.h
tracker和storage共用的一些工具函数,比如根据IP和端口获取tracker的ID诸如此类的
fdfs_trackerd.c:
tracker的入口函数
tracker_dump.c/tracker_dump.h:
实现了fdfs_dump_tracker_global_vars_to_file这个函数
当tracker收到了SIGUSR1或者SIGUSR2信号,将启动sigDumpHandler来调用这个函数,将tracker当前的状态dump进FastDFS跟目录的logs/tracker_dump.log中
关于如何根据该dump文件恢复的,目前没看到,后面再补充
tracker_func.c/tracker_func.h:
实现了tracker_load_from_conf_file这个函数
将tracker的一些基本必要信息,从conf_file中导出
tracker_global.c/tracker_global.h:
记录了tracker使用的一些全局变量
tracker_http_check.c/tracker_http_check.h:
这个模块会对tracker所管理的所有group的可用storage做检测,测试所有的http端口是否可用
tracker_mem.c/tracker_mem.h:
这个模块维护了内存的所有数据,包括集群运行情况等等,提供了save,change和load的接口对集群的总情况进行修改
tracker_nio.c/tracker_nio.h:
nio的模块在common/ioevent和common/ioevent_loop的基础上进行调用
tracker_proto.c/tracker_proto.h:
定义了tracker通信的协议,有时间可以分析下。
tracker_relationship.c/tracker_relationship.h:
定义了tracker之间通信的方式,并且定义了选出leader,ping leader等功能,有时间可以分析下。
tracker_service.c/tracker_service.h:
tracker的逻辑层处理,各个请求在nio后进入work线程,而后分发到各个模块
tracker_status.c/tracker_status.h:
tracker状态的save和load模块
tracker_types.h:
定义了tracker所用到的所有类型
storage文件夹:
fdfs_storage.c: storage的入口函数
storage_dio.c/storage_dio.h:
使用common/fast_task_queue实现了异步的磁盘IO,新任务由storage_dio_queue_push方法入队
同时包含了trunk模块的处理,trunk模块后面再提
storage_disk_recovery.c/storage_disk_recovery.h:
storage的单盘恢复算法,用于故障恢复
storage_dump.c/storage_dump.h:
和tracker_dump原理相同
storage_func.c/storage_func.h:
storage_func_init函数对应着tracker的tracker_load_from_conf_file函数
除此之外,还提供了根据storage_id或者ip判断是否是本机的函数
还提供了一些数据持久化的接口
storage_global.c/storage_global.h:
定义了storage使用的全局变量
storage_ip_changed_dealer.c/storage_ip_changer_dealer.h:
storage实现ip地址改变的模块
1 2 3 4 int storage_get_my_tracker_client_ip () ; int storage_changelog_req () ; int storage_check_ip_changed () ;
storage_nio.c/storage_nio.h:
nio的模块在common/ioevent和common/ioevent_loop的基础上进行调用
storage_param_getter.c/storage_param_getter.h:
storage_get_params_from_tracker函数,顾名思义,从tracker获取自身的参数
storage_service.c/storage_service.h:
storage的逻辑层处理,各个请求在nio后进入work线程,而后分发到各个模块
storage_sync.c/storage_sync.h:
storage的同步模块,众所周知,FastDFS的同步模块是根据时间戳进行的弱一致性同步
tracker_client_thread.c/tracker_client_thread.h
tracker_report的前缀提示的很明显,这部分是storage作为tracker的客户端,向tracker发送心跳,汇报自己的状态等等
全部接口如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int tracker_report_init () ;int tracker_report_destroy () ;int tracker_report_thread_start () ;int kill_tracker_report_threads () ;int tracker_report_join (ConnectionInfo *pTrackerServer, \ const int tracker_index, const bool sync_old_done) ;int tracker_report_storage_status (ConnectionInfo *pTrackerServer, \ FDFSStorageBrief *briefServer) ;int tracker_sync_src_req (ConnectionInfo *pTrackerServer, \ StorageBinLogReader *pReader) ;int tracker_sync_diff_servers (ConnectionInfo *pTrackerServer, \ FDFSStorageBrief *briefServers, const int server_count) ;int tracker_deal_changelog_response (ConnectionInfo *pTrackerServer) ;
trunk_mgr:
这是storage文件的子目录,实现了trunk功能
trunk功能比较零碎,我目前还没搞明白,比如为什么storage和trunk模块交互,storage是作为client出现的,而不是直接调用trunk。
这部分内容应该要单独开一章来分析。
#FastDFS源码解析(2)--------trunk模块分析
trunk功能是把大量小文件合并存储,大量的小文件会大量消耗linux文件系统的node,使树变的过于庞大,降低了读写效率
因此小文件合并存储能显著缓解这一压力
我将对上传和下载流程分析来追踪trunk模块的行为。
在storage_service模块中,storage_service.c/storage_deal_task对请求安装cmd进行分离逻辑来处理
在storage_upload_file中处理上传逻辑
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 static int storage_upload_file (struct fast_task_info *pTask, bool bAppenderFile) { StorageClientInfo *pClientInfo; StorageFileContext *pFileContext; DisconnectCleanFunc clean_func; char *p; char filename[128 ]; char file_ext_name[FDFS_FILE_PREFIX_MAX_LEN + 1 ]; int64_t nInPackLen; int64_t file_offset; int64_t file_bytes; int crc32; int store_path_index; int result; int filename_len; pClientInfo = (StorageClientInfo *)pTask->arg; pFileContext = &(pClientInfo->file_context); nInPackLen = pClientInfo->total_length - sizeof (TrackerHeader); if (nInPackLen < 1 + FDFS_PROTO_PKG_LEN_SIZE + FDFS_FILE_EXT_NAME_MAX_LEN) { logError("file: " __FILE__", line: %d, " \ "cmd=%d, client ip: %s, package size " \ INT64_PRINTF_FORMAT" is not correct, " \ "expect length >= %d" , __LINE__, \ STORAGE_PROTO_CMD_UPLOAD_FILE, \ pTask->client_ip, nInPackLen, \ 1 + FDFS_PROTO_PKG_LEN_SIZE + \ FDFS_FILE_EXT_NAME_MAX_LEN); pClientInfo->total_length = sizeof (TrackerHeader); return EINVAL; } p = pTask->data + sizeof (TrackerHeader); store_path_index = *p++; if (store_path_index == -1 ) { if ((result=storage_get_storage_path_index( \ &store_path_index)) != 0 ) { logError("file: " __FILE__", line: %d, " \ "get_storage_path_index fail, " \ "errno: %d, error info: %s" , __LINE__, \ result, STRERROR(result)); pClientInfo->total_length = sizeof (TrackerHeader); return result; } } else if (store_path_index < 0 || store_path_index >= \ g_fdfs_store_paths.count) { logError("file: " __FILE__", line: %d, " \ "client ip: %s, store_path_index: %d " \ "is invalid" , __LINE__, \ pTask->client_ip, store_path_index); pClientInfo->total_length = sizeof (TrackerHeader); return EINVAL; } file_bytes = buff2long(p); p += FDFS_PROTO_PKG_LEN_SIZE; if (file_bytes < 0 || file_bytes != nInPackLen - \ (1 + FDFS_PROTO_PKG_LEN_SIZE + \ FDFS_FILE_EXT_NAME_MAX_LEN)) { logError("file: " __FILE__", line: %d, " \ "client ip: %s, pkg length is not correct, " \ "invalid file bytes: " INT64_PRINTF_FORMAT \ ", total body length: " INT64_PRINTF_FORMAT, \ __LINE__, pTask->client_ip, file_bytes, nInPackLen); pClientInfo->total_length = sizeof (TrackerHeader); return EINVAL; } memcpy (file_ext_name, p, FDFS_FILE_EXT_NAME_MAX_LEN); *(file_ext_name + FDFS_FILE_EXT_NAME_MAX_LEN) = '\0' ; p += FDFS_FILE_EXT_NAME_MAX_LEN; if ((result=fdfs_validate_filename(file_ext_name)) != 0 ) { logError("file: " __FILE__", line: %d, " \ "client ip: %s, file_ext_name: %s " \ "is invalid!" , __LINE__, \ pTask->client_ip, file_ext_name); pClientInfo->total_length = sizeof (TrackerHeader); return result; } pFileContext->calc_crc32 = true ; pFileContext->calc_file_hash = g_check_file_duplicate; pFileContext->extra_info.upload.start_time = g_current_time; strcpy (pFileContext->extra_info.upload.file_ext_name, file_ext_name); storage_format_ext_name(file_ext_name, \ pFileContext->extra_info.upload.formatted_ext_name); pFileContext->extra_info.upload.trunk_info.path. \ store_path_index = store_path_index; pFileContext->extra_info.upload.file_type = _FILE_TYPE_REGULAR; pFileContext->sync_flag = STORAGE_OP_TYPE_SOURCE_CREATE_FILE; pFileContext->timestamp2log = pFileContext->extra_info.upload.start_time; pFileContext->op = FDFS_STORAGE_FILE_OP_WRITE; if (bAppenderFile) { pFileContext->extra_info.upload.file_type |= \ _FILE_TYPE_APPENDER; } else { if (g_if_use_trunk_file && trunk_check_size( \ TRUNK_CALC_SIZE(file_bytes))) { pFileContext->extra_info.upload.file_type |= \ _FILE_TYPE_TRUNK; } } if (pFileContext->extra_info.upload.file_type & _FILE_TYPE_TRUNK) { FDFSTrunkFullInfo *pTrunkInfo; pFileContext->extra_info.upload.if_sub_path_alloced = true ; pTrunkInfo = &(pFileContext->extra_info.upload.trunk_info); if ((result=trunk_client_trunk_alloc_space( \ TRUNK_CALC_SIZE(file_bytes), pTrunkInfo)) != 0 ) { pClientInfo->total_length = sizeof (TrackerHeader); return result; } clean_func = dio_trunk_write_finish_clean_up; file_offset = TRUNK_FILE_START_OFFSET((*pTrunkInfo)); pFileContext->extra_info.upload.if_gen_filename = true ; trunk_get_full_filename(pTrunkInfo, pFileContext->filename, \ sizeof (pFileContext->filename)); pFileContext->extra_info.upload.before_open_callback = \ dio_check_trunk_file_when_upload; pFileContext->extra_info.upload.before_close_callback = \ dio_write_chunk_header; pFileContext->open_flags = O_RDWR | g_extra_open_file_flags; } else { ... } return storage_write_to_file(pTask, file_offset, file_bytes, \ p - pTask->data, dio_write_file, \ storage_upload_file_done_callback, \ clean_func, store_path_index); }
追踪一下trunk_client_trunk_alloc_space的实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 int trunk_client_trunk_alloc_space (const int file_size, \ FDFSTrunkFullInfo *pTrunkInfo) { int result; ConnectionInfo trunk_server; ConnectionInfo *pTrunkServer; if (g_if_trunker_self) { return trunk_alloc_space(file_size, pTrunkInfo); } if (*(g_trunk_server.ip_addr) == '\0' ) { logError("file: " __FILE__", line: %d, " \ "no trunk server" , __LINE__); return EAGAIN; } memcpy (&trunk_server, &g_trunk_server, sizeof (ConnectionInfo)); if ((pTrunkServer=tracker_connect_server(&trunk_server, &result)) == NULL ) { logError("file: " __FILE__", line: %d, " \ "can't alloc trunk space because connect to trunk " \ "server %s:%d fail, errno: %d" , __LINE__, \ trunk_server.ip_addr, trunk_server.port, result); return result; } result = trunk_client_trunk_do_alloc_space(pTrunkServer, \ file_size, pTrunkInfo); tracker_disconnect_server_ex(pTrunkServer, result != 0 ); return result; }
对直接调用和client_api操作分别追踪
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 nt trunk_alloc_space (const int size, FDFSTrunkFullInfo *pResult) { FDFSTrunkSlot target_slot; FDFSTrunkSlot *pSlot; FDFSTrunkNode *pPreviousNode; FDFSTrunkNode *pTrunkNode; int result; STORAGE_TRUNK_CHECK_STATUS(); target_slot.size = (size > g_slot_min_size) ? size : g_slot_min_size; target_slot.head = NULL ; pPreviousNode = NULL ; pTrunkNode = NULL ; pthread_mutex_lock(&trunk_mem_lock); while (1 ) { pSlot = (FDFSTrunkSlot *)avl_tree_find_ge(tree_info_by_sizes \ + pResult->path.store_path_index, &target_slot); if (pSlot == NULL ) { break ; } pPreviousNode = NULL ; pTrunkNode = pSlot->head; while (pTrunkNode != NULL && \ pTrunkNode->trunk.status == FDFS_TRUNK_STATUS_HOLD) { pPreviousNode = pTrunkNode; pTrunkNode = pTrunkNode->next; } if (pTrunkNode != NULL ) { break ; } target_slot.size = pSlot->size + 1 ; } if (pTrunkNode != NULL ) { if (pPreviousNode == NULL ) { pSlot->head = pTrunkNode->next; if (pSlot->head == NULL ) { trunk_delete_size_tree_entry(pResult->path. \ store_path_index, pSlot); } } else { pPreviousNode->next = pTrunkNode->next; } trunk_free_block_delete(&(pTrunkNode->trunk)); } else { pTrunkNode = trunk_create_trunk_file(pResult->path. \ store_path_index, &result); if (pTrunkNode == NULL ) { pthread_mutex_unlock(&trunk_mem_lock); return result; } } pthread_mutex_unlock(&trunk_mem_lock); result = trunk_split(pTrunkNode, size); if (result != 0 ) { return result; } pTrunkNode->trunk.status = FDFS_TRUNK_STATUS_HOLD; result = trunk_add_free_block(pTrunkNode, true ); if (result == 0 ) { memcpy (pResult, &(pTrunkNode->trunk), \ sizeof (FDFSTrunkFullInfo)); } return result; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 static int trunk_client_trunk_do_alloc_space (ConnectionInfo *pTrunkServer, \ const int file_size, FDFSTrunkFullInfo *pTrunkInfo) { TrackerHeader *pHeader; ... pHeader->cmd = STORAGE_PROTO_CMD_TRUNK_ALLOC_SPACE; if ((result=tcpsenddata_nb(pTrunkServer->sock, out_buff, \ sizeof (out_buff), g_fdfs_network_timeout)) != 0 ) { logError("file: " __FILE__", line: %d, " \ "send data to storage server %s:%d fail, " \ "errno: %d, error info: %s" , __LINE__, \ pTrunkServer->ip_addr, pTrunkServer->port, \ result, STRERROR(result)); return result; } p = (char *)&trunkBuff; if ((result=fdfs_recv_response(pTrunkServer, \ &p, sizeof (FDFSTrunkInfoBuff), &in_bytes)) != 0 ) { return result; } ... return 0 ; }
追踪解析STORAGE_PROTO_CMD_TRUNK_ALLOC_SPACE行为的服务端函数
storage_service.c会将其由storage_server_trunk_alloc_space函数来解析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 static int storage_server_trunk_alloc_space (struct fast_task_info *pTask) { StorageClientInfo *pClientInfo; FDFSTrunkInfoBuff *pApplyBody; char *in_buff; char group_name[FDFS_GROUP_NAME_MAX_LEN + 1 ]; FDFSTrunkFullInfo trunkInfo; int64_t nInPackLen; int file_size; int result; pClientInfo = (StorageClientInfo *)pTask->arg; nInPackLen = pClientInfo->total_length - sizeof (TrackerHeader); pClientInfo->total_length = sizeof (TrackerHeader); CHECK_TRUNK_SERVER(pTask) if (nInPackLen != FDFS_GROUP_NAME_MAX_LEN + 5 ) { logError("file: " __FILE__", line: %d, " \ "cmd=%d, client ip: %s, package size " \ INT64_PRINTF_FORMAT" is not correct, " \ "expect length: %d" , __LINE__, \ STORAGE_PROTO_CMD_TRUNK_ALLOC_SPACE, \ pTask->client_ip, nInPackLen, \ FDFS_GROUP_NAME_MAX_LEN + 5 ); return EINVAL; } in_buff = pTask->data + sizeof (TrackerHeader); memcpy (group_name, in_buff, FDFS_GROUP_NAME_MAX_LEN); *(group_name + FDFS_GROUP_NAME_MAX_LEN) = '\0' ; if (strcmp (group_name, g_group_name) != 0 ) { logError("file: " __FILE__", line: %d, " \ "client ip:%s, group_name: %s " \ "not correct, should be: %s" , \ __LINE__, pTask->client_ip, \ group_name, g_group_name); return EINVAL; } file_size = buff2int(in_buff + FDFS_GROUP_NAME_MAX_LEN); if (file_size < 0 || !trunk_check_size(file_size)) { logError("file: " __FILE__", line: %d, " \ "client ip:%s, invalid file size: %d" , \ __LINE__, pTask->client_ip, file_size); return EINVAL; } trunkInfo.path.store_path_index = *(in_buff+FDFS_GROUP_NAME_MAX_LEN+4 ); if ((result=trunk_alloc_space(file_size, &trunkInfo)) != 0 ) { return result; } pApplyBody = (FDFSTrunkInfoBuff *)(pTask->data+sizeof (TrackerHeader)); pApplyBody->store_path_index = trunkInfo.path.store_path_index; pApplyBody->sub_path_high = trunkInfo.path.sub_path_high; pApplyBody->sub_path_low = trunkInfo.path.sub_path_low; int2buff(trunkInfo.file.id, pApplyBody->id); int2buff(trunkInfo.file.offset, pApplyBody->offset); int2buff(trunkInfo.file.size, pApplyBody->size); pClientInfo->total_length = sizeof (TrackerHeader) + \ sizeof (FDFSTrunkInfoBuff); return 0 ; }
trunk_client_trunk_alloc_space会向同组内唯一的trunk_server申请空间
最终的实现还是trunk_alloc_space函数
trunk相当于一个KV吧。介个会不会出现单点问题,这台trunk失效以后如何冗余故障,接着往下分析看看
以下这段函数是在tracker_client_thread里面的,大致是storage和tracker的一个交互,如果有故障冗余,这里应该存在机制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 static int tracker_check_response (ConnectionInfo *pTrackerServer, \ bool *bServerPortChanged) { int64_t nInPackLen; TrackerHeader resp; int server_count; int result; char in_buff[1 + (2 + FDFS_MAX_SERVERS_EACH_GROUP) * \ sizeof (FDFSStorageBrief)]; FDFSStorageBrief *pBriefServers; char *pFlags; ... if ((*pFlags) & FDFS_CHANGE_FLAG_TRACKER_LEADER) { ... } if ((*pFlags) & FDFS_CHANGE_FLAG_TRUNK_SERVER) { if (server_count < 1 ) { logError("file: " __FILE__", line: %d, " \ "tracker server %s:%d, reponse server " \ "count: %d < 1" , __LINE__, \ pTrackerServer->ip_addr, \ pTrackerServer->port, server_count); return EINVAL; } if (!g_if_use_trunk_file) { logInfo("file: " __FILE__", line: %d, " \ "reload parameters from tracker server" , \ __LINE__); storage_get_params_from_tracker(); } if (!g_if_use_trunk_file) { logWarning("file: " __FILE__", line: %d, " \ "tracker server %s:%d, " \ "my g_if_use_trunk_file is false, " \ "can't support trunk server!" , \ __LINE__, pTrackerServer->ip_addr, \ pTrackerServer->port); } else { memcpy (g_trunk_server.ip_addr, pBriefServers->ip_addr, \ IP_ADDRESS_SIZE - 1 ); *(g_trunk_server.ip_addr + (IP_ADDRESS_SIZE - 1 )) = '\0' ; g_trunk_server.port = buff2int(pBriefServers->port); if (is_local_host_ip(g_trunk_server.ip_addr) && \ g_trunk_server.port == g_server_port) { if (g_if_trunker_self) { logWarning("file: " __FILE__", line: %d, " \ "I am already the trunk server %s:%d, " \ "may be the tracker server restart" , \ __LINE__, g_trunk_server.ip_addr, \ g_trunk_server.port); } else { logInfo("file: " __FILE__", line: %d, " \ "I am the the trunk server %s:%d" , __LINE__, \ g_trunk_server.ip_addr, g_trunk_server.port); tracker_fetch_trunk_fid(pTrackerServer); g_if_trunker_self = true ; if ((result=storage_trunk_init()) != 0 ) { return result; } if (g_trunk_create_file_advance && \ g_trunk_create_file_interval > 0 ) { ScheduleArray scheduleArray; ScheduleEntry entries[1 ]; entries[0 ].id = TRUNK_FILE_CREATOR_TASK_ID; entries[0 ].time_base = g_trunk_create_file_time_base; entries[0 ].interval = g_trunk_create_file_interval; entries[0 ].task_func = trunk_create_trunk_file_advance; entries[0 ].func_args = NULL ; scheduleArray.count = 1 ; scheduleArray.entries = entries; sched_add_entries(&scheduleArray); } trunk_sync_thread_start_all(); } } else { logInfo("file: " __FILE__", line: %d, " \ "the trunk server is %s:%d" , __LINE__, \ g_trunk_server.ip_addr, g_trunk_server.port); if (g_if_trunker_self) { int saved_trunk_sync_thread_count; logWarning("file: " __FILE__", line: %d, " \ "I am the old trunk server, " \ "the new trunk server is %s:%d" , \ __LINE__, g_trunk_server.ip_addr, \ g_trunk_server.port); tracker_report_trunk_fid(pTrackerServer); g_if_trunker_self = false ; saved_trunk_sync_thread_count = \ g_trunk_sync_thread_count; if (saved_trunk_sync_thread_count > 0 ) { logInfo("file: " __FILE__", line: %d, " \ "waiting %d trunk sync " \ "threads exit ..." , __LINE__, \ saved_trunk_sync_thread_count); } while (g_trunk_sync_thread_count > 0 ) { usleep(50000 ); } if (saved_trunk_sync_thread_count > 0 ) { logInfo("file: " __FILE__", line: %d, " \ "%d trunk sync threads exited" ,\ __LINE__, \ saved_trunk_sync_thread_count); } storage_trunk_destroy_ex(true ); if (g_trunk_create_file_advance && \ g_trunk_create_file_interval > 0 ) { sched_del_entry(TRUNK_FILE_CREATOR_TASK_ID); } } } } pBriefServers += 1 ; server_count -= 1 ; } if (!((*pFlags) & FDFS_CHANGE_FLAG_GROUP_SERVER)) { return 0 ; } if (*bServerPortChanged) { if (!g_use_storage_id) { FDFSStorageBrief *pStorageEnd; FDFSStorageBrief *pStorage; *bServerPortChanged = false ; pStorageEnd = pBriefServers + server_count; for (pStorage=pBriefServers; pStorage<pStorageEnd; pStorage++) { if (strcmp (pStorage->id, g_my_server_id_str) == 0 ) { continue ; } tracker_rename_mark_files(pStorage->ip_addr, \ g_last_server_port, pStorage->ip_addr, \ g_server_port); } } if (g_server_port != g_last_server_port) { g_last_server_port = g_server_port; if ((result=storage_write_to_sync_ini_file()) != 0 ) { return result; } } } return tracker_merge_servers(pTrackerServer, \ pBriefServers, server_count); }
可以看到,trunk的失败确实是存在冗余机制,由tracker来选出trunk。
trunk的分析暂告一段落,删除文件后是否存在文件空洞,空洞的利用率如何,都得用数据说话才行哈。
总结:
每个组都有唯一的trunk leader,组内所有trunk文件的信息,由这个trunk leader内部组织的avl树来保存。
上传文件后,storage会向trunk leader发起申请空间的请求,这时trunk leader会使用一个全局的锁,获得了trunk存储的位置后,storage在本地写磁盘。
下载文件时,trunk信息在文件名里面已经包含,只需要直接读即可。
使用trunk方式主要是为了解决node过多造成读写性能下降的问题,但是引入trunk方式本身也会造成一定的性能损耗。
目前感觉我对trunk功能还是hold不住,包括如果trunk出错,怎么样恢复trunk文件的数据,因为没有提供的官方的工具,所以不太敢用。
以后如果有需求在跟进,先告一段落了吧。
#FastDFS源码解析(3)--------通信协议分析
就上传和下载进行分析,其他暂时略过
上传:
1 根据ip,port连接上tracker
2 发送一个10字节的包,其中第9个字节为TRACKER_PROTO_CMD_SERVICE_QUERY_STORE_WITHOUT_GROUP_ONE,也就是101
3 接受一个10字节的包,其中第10个字节为返回状态,如果是0,说明一切正常
4 接受的这个包,0-8字节是下面要接收的包的大小,通过以下算法可以还原成数字
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 int64_t buff2long (const char *buff) { unsigned char *p; p = (unsigned char *)buff; return (((int64_t )(*p)) << 56 ) | \ (((int64_t )(*(p+1 ))) << 48 ) | \ (((int64_t )(*(p+2 ))) << 40 ) | \ (((int64_t )(*(p+3 ))) << 32 ) | \ (((int64_t )(*(p+4 ))) << 24 ) | \ (((int64_t )(*(p+5 ))) << 16 ) | \ (((int64_t )(*(p+6 ))) << 8 ) | \ ((int64_t )(*(p+7 ))); } void long2buff (int64_t n, char *buff) { unsigned char *p; p = (unsigned char *)buff; *p++ = (n >> 56 ) & 0xFF ; *p++ = (n >> 48 ) & 0xFF ; *p++ = (n >> 40 ) & 0xFF ; *p++ = (n >> 32 ) & 0xFF ; *p++ = (n >> 24 ) & 0xFF ; *p++ = (n >> 16 ) & 0xFF ; *p++ = (n >> 8 ) & 0xFF ; *p++ = n & 0xFF ; }
5 读完这个数字对应的字节数目,这个数字应当有TRACKER_QUERY_STORAGE_STORE_BODY_LEN长,否则出错
1 2 #define TRACKER_QUERY_STORAGE_STORE_BODY_LEN (FDFS_GROUP_NAME_MAX_LEN \ + IP_ADDRESS_SIZE - 1 + FDFS_PROTO_PKG_LEN_SIZE + 1)
也就是16+16-1+8+1 = 40
6 这40个字节,头16字节是组名,接着15字节是IP地址,接着8字节是端口号,还是根据buff2long算法还原成数字,最后1字节是store_path_index
tracker交互完毕,此时进行storage操作
7 根据ip和端口连接storage
8 发送25字节的包
头10字节是TrackerHeader一样的结构,其中1-8字节的内容为filesize+这个包的大小(25)-头的大小(10),也就是file_size+15这个数,通过long2buff,转换的8字节字串,然后其中第9字节的内容是STORAGE_PROTO_CMD_UPLOAD_FILE,也就是11
第11字节是刚才接受的storage_path_index
第12-19字节是file_size,通过long2buff算法转换为8字节字串
19-25字节是ext_name相关,这里设置为0即可
9 发送file_size字节内容,即为文件信息
10 接受一个10字节的包,其中第10个字节为返回状态,如果是0,说明一切正常
11 接受的这个包,0-8字节是下面要接收的包的大小,通过buff2long还原为数字
12 这个数字应该大于FDFS_GROUP_NAME_MAX_LEN,也就是16字节,否则出错
13 头16字节为组名,后面全部的字节为remote_filename
14 上传流程完成
下载:
下载需要上传时rsp返回的文件ID,这里命名为file_id
1 连接tracker
2 切分file_id,第一个/前出现的即为group_name,后面的都是remote_filename
3 发送一个10字节的pHeader,其中1-8字节是FDFS_GROUP_NAME_MAX_LEN(值为16) 加上 remote_filename的长度,通过long2buff转化而成的
第9字节是CMD TRACKER_PROTO_CMD_SERVICE_QUERY_FETCH_ONE,即为102
4 发送16字节是group_name
5 发送remote_filename这个字串
6 接受一个10字节的包,其中第10个字节为返回状态,如果是0,说明一切正常
7 接受的这个包,1-8字节是下面要接收的包的大小,通过buff2long可以还原成数字
8 读完这个数字对应的字节数目,这个数字应当有TRACKER_QUERY_STORAGE_FETCH_BODY_LEN(TRACKER_QUERY_STORAGE_STORE_BODY_LEN - 1,也就是39)长,否则出错
9 这39个字节,头16字节是组名(下载逻辑时可以忽略),接着15字节是IP地址,接着8字节是端口号,还是根据buff2long算法还原成数字
10 和tracker的交互完成,下面是storage
11 根据ip和端口连接storage
12 发送一个pHeader+file_offset+download_bytes+group_name(补全16字节)+filename的数据包
也就是10+8+8+16+filename_size
1-8字节是8+8+16+filename_size的大小根据long2buff转换的字串
9字节是STORAGE_PROTO_CMD_DOWNLOAD_FILE也就是14
11-18字节是file_offset的long2buff字串
19-26是download_bytes的long2buff字串
27-42是group_name
再往后就是finename
13 接受一个10字节的包,其中第10个字节为返回状态,如果是0,说明一切正常
14 接受的这个包,1-8字节是下面要接收的包的大小,通过buff2long可以还原成数字
15 将接收到的包写入文件,一次下载逻辑完毕
上传下载是最经典的逻辑,其他逻辑都可以从这里衍生,不做详细介绍了
#FastDFS源码解析(4)--------storage运行流程分析
大致来分析一下fdfs storage是如何提供服务的,以上传文件为例。
从storage的初始化函数来入手
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 int storage_service_init () { int result; int bytes; struct storage_nio_thread_data *pThreadData ; struct storage_nio_thread_data *pDataEnd ; pthread_t tid; pthread_attr_t thread_attr; if ((result=init_pthread_lock(&g_storage_thread_lock)) != 0 ) { return result; } if ((result=init_pthread_lock(&path_index_thread_lock)) != 0 ) { return result; } if ((result=init_pthread_lock(&stat_count_thread_lock)) != 0 ) { return result; } if ((result=init_pthread_attr(&thread_attr, g_thread_stack_size)) != 0 ) { logError("file: " __FILE__", line: %d, " \ "init_pthread_attr fail, program exit!" , __LINE__); return result; } if ((result=free_queue_init(g_max_connections, g_buff_size, \ g_buff_size, sizeof (StorageClientInfo))) != 0 ) { return result; } bytes = sizeof (struct storage_nio_thread_data) * g_work_threads; g_nio_thread_data = (struct storage_nio_thread_data *)malloc (bytes); if (g_nio_thread_data == NULL ) { logError("file: " __FILE__", line: %d, " \ "malloc %d bytes fail, errno: %d, error info: %s" , \ __LINE__, bytes, errno, STRERROR(errno)); return errno != 0 ? errno : ENOMEM; } memset (g_nio_thread_data, 0 , bytes); g_storage_thread_count = 0 ; pDataEnd = g_nio_thread_data + g_work_threads; for (pThreadData=g_nio_thread_data; pThreadData<pDataEnd; pThreadData++) { if (ioevent_init(&pThreadData->thread_data.ev_puller, g_max_connections + 2 , 1000 , 0 ) != 0 ) { result = errno != 0 ? errno : ENOMEM; logError("file: " __FILE__", line: %d, " \ "ioevent_init fail, " \ "errno: %d, error info: %s" , \ __LINE__, result, STRERROR(result)); return result; } result = fast_timer_init(&pThreadData->thread_data.timer, 2 * g_fdfs_network_timeout, g_current_time); if (result != 0 ) { logError("file: " __FILE__", line: %d, " \ "fast_timer_init fail, " \ "errno: %d, error info: %s" , \ __LINE__, result, STRERROR(result)); return result; } if (pipe(pThreadData->thread_data.pipe_fds) != 0 ) { result = errno != 0 ? errno : EPERM; logError("file: " __FILE__", line: %d, " \ "call pipe fail, " \ "errno: %d, error info: %s" , \ __LINE__, result, STRERROR(result)); break ; } #if defined(OS_LINUX) if ((result=fd_add_flags(pThreadData->thread_data.pipe_fds[0 ], \ O_NONBLOCK | O_NOATIME)) != 0 ) { break ; } #else if ((result=fd_add_flags(pThreadData->thread_data.pipe_fds[0 ], \ O_NONBLOCK)) != 0 ) { break ; } #endif if ((result=pthread_create(&tid, &thread_attr, \ work_thread_entrance, pThreadData)) != 0 ) { logError("file: " __FILE__", line: %d, " \ "create thread failed, startup threads: %d, " \ "errno: %d, error info: %s" , \ __LINE__, g_storage_thread_count, \ result, STRERROR(result)); break ; } else { if ((result=pthread_mutex_lock(&g_storage_thread_lock)) != 0 ) { logError("file: " __FILE__", line: %d, " \ "call pthread_mutex_lock fail, " \ "errno: %d, error info: %s" , \ __LINE__, result, STRERROR(result)); } g_storage_thread_count++; if ((result=pthread_mutex_unlock(&g_storage_thread_lock)) != 0 ) { logError("file: " __FILE__", line: %d, " \ "call pthread_mutex_lock fail, " \ "errno: %d, error info: %s" , \ __LINE__, result, STRERROR(result)); } } } pthread_attr_destroy(&thread_attr); last_stat_change_count = g_stat_change_count; if (result != 0 ) { return result; } return result; }
跟进工作线程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 static void *work_thread_entrance (void * arg) { int result; struct storage_nio_thread_data *pThreadData ; pThreadData = (struct storage_nio_thread_data *)arg; if (g_check_file_duplicate) { if ((result=fdht_copy_group_array(&(pThreadData->group_array),\ &g_group_array)) != 0 ) { pthread_mutex_lock(&g_storage_thread_lock); g_storage_thread_count--; pthread_mutex_unlock(&g_storage_thread_lock); return NULL ; } } ioevent_loop(&pThreadData->thread_data, storage_recv_notify_read, task_finish_clean_up, &g_continue_flag); ioevent_destroy(&pThreadData->thread_data.ev_puller); if (g_check_file_duplicate) { if (g_keep_alive) { fdht_disconnect_all_servers(&(pThreadData->group_array)); } fdht_free_group_array(&(pThreadData->group_array)); } if ((result=pthread_mutex_lock(&g_storage_thread_lock)) != 0 ) { logError("file: " __FILE__", line: %d, " \ "call pthread_mutex_lock fail, " \ "errno: %d, error info: %s" , \ __LINE__, result, STRERROR(result)); } g_storage_thread_count--; if ((result=pthread_mutex_unlock(&g_storage_thread_lock)) != 0 ) { logError("file: " __FILE__", line: %d, " \ "call pthread_mutex_lock fail, " \ "errno: %d, error info: %s" , \ __LINE__, result, STRERROR(result)); } logDebug("file: " __FILE__", line: %d, " \ "nio thread exited, thread count: %d" , \ __LINE__, g_storage_thread_count); return NULL ; }
除了work_thread_entrance线程,还有一个叫做accept_thread_entrance的线程,专门用来accept请求,防止大量的操作阻塞了accept的性能
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 static void *accept_thread_entrance (void * arg) { int server_sock; int incomesock; struct sockaddr_in inaddr ; socklen_t sockaddr_len; in_addr_t client_addr; char szClientIp[IP_ADDRESS_SIZE]; long task_addr; struct fast_task_info *pTask ; StorageClientInfo *pClientInfo; struct storage_nio_thread_data *pThreadData ; server_sock = (long )arg; while (g_continue_flag) { sockaddr_len = sizeof (inaddr); incomesock = accept(server_sock, (struct sockaddr*)&inaddr, \ &sockaddr_len); if (incomesock < 0 ) { if (!(errno == EINTR || errno == EAGAIN)) { logError("file: " __FILE__", line: %d, " \ "accept failed, " \ "errno: %d, error info: %s" , \ __LINE__, errno, STRERROR(errno)); } continue ; } client_addr = getPeerIpaddr(incomesock, \ szClientIp, IP_ADDRESS_SIZE); if (g_allow_ip_count >= 0 ) { if (bsearch(&client_addr, g_allow_ip_addrs, \ g_allow_ip_count, sizeof (in_addr_t ), \ cmp_by_ip_addr_t ) == NULL ) { logError("file: " __FILE__", line: %d, " \ "ip addr %s is not allowed to access" , \ __LINE__, szClientIp); close(incomesock); continue ; } } if (tcpsetnonblockopt(incomesock) != 0 ) { close(incomesock); continue ; } pTask = free_queue_pop(); if (pTask == NULL ) { logError("file: " __FILE__", line: %d, " \ "malloc task buff failed" , \ __LINE__); close(incomesock); continue ; } pClientInfo = (StorageClientInfo *)pTask->arg; pTask->event.fd = incomesock; pClientInfo->stage = FDFS_STORAGE_STAGE_NIO_INIT; pClientInfo->nio_thread_index = pTask->event.fd % g_work_threads; pThreadData = g_nio_thread_data + pClientInfo->nio_thread_index; strcpy (pTask->client_ip, szClientIp); task_addr = (long )pTask; if (write(pThreadData->thread_data.pipe_fds[1 ], &task_addr, \ sizeof (task_addr)) != sizeof (task_addr)) { close(incomesock); free_queue_push(pTask); logError("file: " __FILE__", line: %d, " \ "call write failed, " \ "errno: %d, error info: %s" , \ __LINE__, errno, STRERROR(errno)); } } return NULL ; }
关注一下storage_recv_notify_read函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 void storage_recv_notify_read (int sock, short event, void *arg) { struct fast_task_info *pTask ; StorageClientInfo *pClientInfo; long task_addr; int64_t remain_bytes; int bytes; int result; while (1 ) { if ((bytes=read(sock, &task_addr, sizeof (task_addr))) < 0 ) { if (!(errno == EAGAIN || errno == EWOULDBLOCK)) { logError("file: " __FILE__", line: %d, " \ "call read failed, " \ "errno: %d, error info: %s" , \ __LINE__, errno, STRERROR(errno)); } break ; } else if (bytes == 0 ) { logError("file: " __FILE__", line: %d, " \ "call read failed, end of file" , __LINE__); break ; } pTask = (struct fast_task_info *)task_addr; pClientInfo = (StorageClientInfo *)pTask->arg; if (pTask->event.fd < 0 ) { return ; } if (pClientInfo->stage & FDFS_STORAGE_STAGE_DIO_THREAD) { pClientInfo->stage &= ~FDFS_STORAGE_STAGE_DIO_THREAD; } switch (pClientInfo->stage) { case FDFS_STORAGE_STAGE_NIO_INIT: result = storage_nio_init(pTask); break ; case FDFS_STORAGE_STAGE_NIO_RECV: pTask->offset = 0 ; remain_bytes = pClientInfo->total_length - \ pClientInfo->total_offset; if (remain_bytes > pTask->size) { pTask->length = pTask->size; } else { pTask->length = remain_bytes; } if (set_recv_event(pTask) == 0 ) { client_sock_read(pTask->event.fd, IOEVENT_READ, pTask); } result = 0 ; break ; case FDFS_STORAGE_STAGE_NIO_SEND: result = storage_send_add_event(pTask); break ; case FDFS_STORAGE_STAGE_NIO_CLOSE: result = EIO; break ; default : logError("file: " __FILE__", line: %d, " \ "invalid stage: %d" , __LINE__, \ pClientInfo->stage); result = EINVAL; break ; } if (result != 0 ) { add_to_deleted_list(pTask); } } }
初始化实质上是将task对应的fd,注册client_sock_read函数 同时将task状态设置为FDFS_STORAGE_STAGE_NIO_RECV
1 2 3 4 5 6 7 8 9 10 11 12 13 static int storage_nio_init (struct fast_task_info *pTask) { StorageClientInfo *pClientInfo; struct storage_nio_thread_data *pThreadData ; pClientInfo = (StorageClientInfo *)pTask->arg; pThreadData = g_nio_thread_data + pClientInfo->nio_thread_index; pClientInfo->stage = FDFS_STORAGE_STAGE_NIO_RECV; return ioevent_set(pTask, &pThreadData->thread_data, pTask->event.fd, IOEVENT_READ, client_sock_read, g_fdfs_network_timeout); }
看看这个client_sock_read函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 static void client_sock_read (int sock, short event, void *arg) { int bytes; int recv_bytes; struct fast_task_info *pTask ; StorageClientInfo *pClientInfo; pTask = (struct fast_task_info *)arg; pClientInfo = (StorageClientInfo *)pTask->arg; if (pClientInfo->canceled) { return ; } if (pClientInfo->stage != FDFS_STORAGE_STAGE_NIO_RECV) { if (event & IOEVENT_TIMEOUT) { pTask->event.timer.expires = g_current_time + g_fdfs_network_timeout; fast_timer_add(&pTask->thread_data->timer, &pTask->event.timer); } return ; } if (event & IOEVENT_TIMEOUT) { if (pClientInfo->total_offset == 0 && pTask->req_count > 0 ) { pTask->event.timer.expires = g_current_time + g_fdfs_network_timeout; fast_timer_add(&pTask->thread_data->timer, &pTask->event.timer); } else { logError("file: " __FILE__", line: %d, " \ "client ip: %s, recv timeout, " \ "recv offset: %d, expect length: %d" , \ __LINE__, pTask->client_ip, \ pTask->offset, pTask->length); task_finish_clean_up(pTask); } return ; } if (event & IOEVENT_ERROR) { logError("file: " __FILE__", line: %d, " \ "client ip: %s, recv error event: %d, " "close connection" , __LINE__, pTask->client_ip, event); task_finish_clean_up(pTask); return ; } fast_timer_modify(&pTask->thread_data->timer, &pTask->event.timer, g_current_time + g_fdfs_network_timeout); while (1 ) { if (pClientInfo->total_length == 0 ) { recv_bytes = sizeof (TrackerHeader) - pTask->offset; } else { recv_bytes = pTask->length - pTask->offset; } bytes = recv(sock, pTask->data + pTask->offset, recv_bytes, 0 ); if (bytes < 0 ) { if (errno == EAGAIN || errno == EWOULDBLOCK) { } else { logError("file: " __FILE__", line: %d, " \ "client ip: %s, recv failed, " \ "errno: %d, error info: %s" , \ __LINE__, pTask->client_ip, \ errno, STRERROR(errno)); task_finish_clean_up(pTask); } return ; } else if (bytes == 0 ) { logDebug("file: " __FILE__", line: %d, " \ "client ip: %s, recv failed, " \ "connection disconnected." , \ __LINE__, pTask->client_ip); task_finish_clean_up(pTask); return ; } if (pClientInfo->total_length == 0 ) { if (pTask->offset + bytes < sizeof (TrackerHeader)) { pTask->offset += bytes; return ; } pClientInfo->total_length=buff2long(((TrackerHeader *) \ pTask->data)->pkg_len); if (pClientInfo->total_length < 0 ) { logError("file: " __FILE__", line: %d, " \ "client ip: %s, pkg length: " \ INT64_PRINTF_FORMAT" < 0" , \ __LINE__, pTask->client_ip, \ pClientInfo->total_length); task_finish_clean_up(pTask); return ; } pClientInfo->total_length += sizeof (TrackerHeader); if (pClientInfo->total_length > pTask->size) { pTask->length = pTask->size; } else { pTask->length = pClientInfo->total_length; } } pTask->offset += bytes; if (pTask->offset >= pTask->length) { if (pClientInfo->total_offset + pTask->length >= \ pClientInfo->total_length) { pClientInfo->stage = FDFS_STORAGE_STAGE_NIO_SEND; pTask->req_count++; } if (pClientInfo->total_offset == 0 ) { pClientInfo->total_offset = pTask->length; storage_deal_task(pTask); } else { pClientInfo->total_offset += pTask->length; storage_dio_queue_push(pTask); } return ; } } return ; }
storage_deal_task将上传请求分发给storage_upload_file
storage_upload_file注册一些基本的函数而后调用 storage_write_to_file
1 2 3 4 5 6 7 8 9 10 static int storage_upload_file (struct fast_task_info *pTask, bool bAppenderFile) { ... return storage_write_to_file(pTask, file_offset, file_bytes, \ p - pTask->data, dio_write_file, \ storage_upload_file_done_callback, \ clean_func, store_path_index); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 static int storage_write_to_file (struct fast_task_info *pTask, \ const int64_t file_offset, const int64_t upload_bytes, \ const int buff_offset, TaskDealFunc deal_func, \ FileDealDoneCallback done_callback, \ DisconnectCleanFunc clean_func, const int store_path_index) { StorageClientInfo *pClientInfo; StorageFileContext *pFileContext; int result; pClientInfo = (StorageClientInfo *)pTask->arg; pFileContext = &(pClientInfo->file_context); pClientInfo->deal_func = deal_func; pClientInfo->clean_func = clean_func; pFileContext->fd = -1 ; pFileContext->buff_offset = buff_offset; pFileContext->offset = file_offset; pFileContext->start = file_offset; pFileContext->end = file_offset + upload_bytes; pFileContext->dio_thread_index = storage_dio_get_thread_index( \ pTask, store_path_index, pFileContext->op); pFileContext->done_callback = done_callback; if (pFileContext->calc_crc32) { pFileContext->crc32 = CRC32_XINIT; } if (pFileContext->calc_file_hash) { if (g_file_signature_method == STORAGE_FILE_SIGNATURE_METHOD_HASH) { INIT_HASH_CODES4(pFileContext->file_hash_codes) } else { my_md5_init(&pFileContext->md5_context); } } if ((result=storage_dio_queue_push(pTask)) != 0 ) { pClientInfo->total_length = sizeof (TrackerHeader); return result; } return STORAGE_STATUE_DEAL_FILE; }
压入磁盘队列的处理函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 int storage_dio_queue_push (struct fast_task_info *pTask) { StorageClientInfo *pClientInfo; StorageFileContext *pFileContext; struct storage_dio_context *pContext ; int result; pClientInfo = (StorageClientInfo *)pTask->arg; pFileContext = &(pClientInfo->file_context); pContext = g_dio_contexts + pFileContext->dio_thread_index; pClientInfo->stage |= FDFS_STORAGE_STAGE_DIO_THREAD; if ((result=task_queue_push(&(pContext->queue ), pTask)) != 0 ) { add_to_deleted_list(pTask); return result; } if ((result=pthread_cond_signal(&(pContext->cond))) != 0 ) { logError("file: " __FILE__", line: %d, " \ "pthread_cond_signal fail, " \ "errno: %d, error info: %s" , \ __LINE__, result, STRERROR(result)); add_to_deleted_list(pTask); return result; } return 0 ; }
下面就是磁盘线程取task了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 static void *dio_thread_entrance (void * arg) { int result; struct storage_dio_context *pContext ; struct fast_task_info *pTask ; pContext = (struct storage_dio_context *)arg; pthread_mutex_lock(&(pContext->lock)); while (g_continue_flag) { if ((result=pthread_cond_wait(&(pContext->cond), \ &(pContext->lock))) != 0 ) { logError("file: " __FILE__", line: %d, " \ "call pthread_cond_wait fail, " \ "errno: %d, error info: %s" , \ __LINE__, result, STRERROR(result)); } while ((pTask=task_queue_pop(&(pContext->queue ))) != NULL ) { ((StorageClientInfo *)pTask->arg)->deal_func(pTask); } } pthread_mutex_unlock(&(pContext->lock)); if ((result=pthread_mutex_lock(&g_dio_thread_lock)) != 0 ) { logError("file: " __FILE__", line: %d, " \ "call pthread_mutex_lock fail, " \ "errno: %d, error info: %s" , \ __LINE__, result, STRERROR(result)); } g_dio_thread_count--; if ((result=pthread_mutex_unlock(&g_dio_thread_lock)) != 0 ) { logError("file: " __FILE__", line: %d, " \ "call pthread_mutex_lock fail, " \ "errno: %d, error info: %s" , \ __LINE__, result, STRERROR(result)); } logDebug("file: " __FILE__", line: %d, " \ "dio thread exited, thread count: %d" , \ __LINE__, g_dio_thread_count); return NULL ; }
对于上传任务来说,deal_task实际上是do_write_file
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 int dio_write_file (struct fast_task_info *pTask) { StorageClientInfo *pClientInfo; StorageFileContext *pFileContext; int result; int write_bytes; char *pDataBuff; pClientInfo = (StorageClientInfo *)pTask->arg; pFileContext = &(pClientInfo->file_context); result = 0 ; do { if (pFileContext->fd < 0 ) { if (pFileContext->extra_info.upload.before_open_callback!=NULL ) { result = pFileContext->extra_info.upload. \ before_open_callback(pTask); if (result != 0 ) { break ; } } if ((result=dio_open_file(pFileContext)) != 0 ) { break ; } } pDataBuff = pTask->data + pFileContext->buff_offset; write_bytes = pTask->length - pFileContext->buff_offset; if (write(pFileContext->fd, pDataBuff, write_bytes) != write_bytes) { result = errno != 0 ? errno : EIO; logError("file: " __FILE__", line: %d, " \ "write to file: %s fail, fd=%d, write_bytes=%d, " \ "errno: %d, error info: %s" , \ __LINE__, pFileContext->filename, \ pFileContext->fd, write_bytes, \ result, STRERROR(result)); } pthread_mutex_lock(&g_dio_thread_lock); g_storage_stat.total_file_write_count++; if (result == 0 ) { g_storage_stat.success_file_write_count++; } pthread_mutex_unlock(&g_dio_thread_lock); if (result != 0 ) { break ; } if (pFileContext->calc_crc32) { pFileContext->crc32 = CRC32_ex(pDataBuff, write_bytes, \ pFileContext->crc32); } if (pFileContext->calc_file_hash) { if (g_file_signature_method == STORAGE_FILE_SIGNATURE_METHOD_HASH) { CALC_HASH_CODES4(pDataBuff, write_bytes, \ pFileContext->file_hash_codes) } else { my_md5_update(&pFileContext->md5_context, \ (unsigned char *)pDataBuff, write_bytes); } } pFileContext->offset += write_bytes; if (pFileContext->offset < pFileContext->end) { pFileContext->buff_offset = 0 ; storage_nio_notify(pTask); } else { if (pFileContext->calc_crc32) { pFileContext->crc32 = CRC32_FINAL( \ pFileContext->crc32); } if (pFileContext->calc_file_hash) { if (g_file_signature_method == STORAGE_FILE_SIGNATURE_METHOD_HASH) { FINISH_HASH_CODES4(pFileContext->file_hash_codes) } else { my_md5_final((unsigned char *)(pFileContext-> \ file_hash_codes), &pFileContext->md5_context); } } if (pFileContext->extra_info.upload.before_close_callback != NULL ) { result = pFileContext->extra_info.upload. \ before_close_callback(pTask); } close(pFileContext->fd); pFileContext->fd = -1 ; if (pFileContext->done_callback != NULL ) { pFileContext->done_callback(pTask, result); } } return 0 ; } while (0 ); pClientInfo->clean_func(pTask); if (pFileContext->done_callback != NULL ) { pFileContext->done_callback(pTask, result); } return result; }
pFileContext->done_callback对应了storage_upload_file_done_callback
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 static void storage_upload_file_done_callback (struct fast_task_info *pTask, \ const int err_no) { StorageClientInfo *pClientInfo; StorageFileContext *pFileContext; TrackerHeader *pHeader; int result; pClientInfo = (StorageClientInfo *)pTask->arg; pFileContext = &(pClientInfo->file_context); if (pFileContext->extra_info.upload.file_type & _FILE_TYPE_TRUNK) { result = trunk_client_trunk_alloc_confirm( \ &(pFileContext->extra_info.upload.trunk_info), err_no); if (err_no != 0 ) { result = err_no; } } else { result = err_no; } if (result == 0 ) { result = storage_service_upload_file_done(pTask); if (result == 0 ) { if (pFileContext->create_flag & STORAGE_CREATE_FLAG_FILE) { result = storage_binlog_write(\ pFileContext->timestamp2log, \ STORAGE_OP_TYPE_SOURCE_CREATE_FILE, \ pFileContext->fname2log); } } } if (result == 0 ) { int filename_len; char *p; if (pFileContext->create_flag & STORAGE_CREATE_FLAG_FILE) { CHECK_AND_WRITE_TO_STAT_FILE3_WITH_BYTES( \ g_storage_stat.total_upload_count, \ g_storage_stat.success_upload_count, \ g_storage_stat.last_source_update, \ g_storage_stat.total_upload_bytes, \ g_storage_stat.success_upload_bytes, \ pFileContext->end - pFileContext->start) } filename_len = strlen (pFileContext->fname2log); pClientInfo->total_length = sizeof (TrackerHeader) + \ FDFS_GROUP_NAME_MAX_LEN + filename_len; p = pTask->data + sizeof (TrackerHeader); memcpy (p, pFileContext->extra_info.upload.group_name, \ FDFS_GROUP_NAME_MAX_LEN); p += FDFS_GROUP_NAME_MAX_LEN; memcpy (p, pFileContext->fname2log, filename_len); } else { pthread_mutex_lock(&stat_count_thread_lock); if (pFileContext->create_flag & STORAGE_CREATE_FLAG_FILE) { g_storage_stat.total_upload_count++; g_storage_stat.total_upload_bytes += \ pClientInfo->total_offset; } pthread_mutex_unlock(&stat_count_thread_lock); pClientInfo->total_length = sizeof (TrackerHeader); } STORAGE_ACCESS_LOG(pTask, ACCESS_LOG_ACTION_UPLOAD_FILE, result); pClientInfo->total_offset = 0 ; pTask->length = pClientInfo->total_length; pHeader = (TrackerHeader *)pTask->data; pHeader->status = result; pHeader->cmd = STORAGE_PROTO_CMD_RESP; long2buff(pClientInfo->total_length - sizeof (TrackerHeader), \ pHeader->pkg_len); storage_nio_notify(pTask); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 void storage_recv_notify_read (int sock, short event, void *arg) { ... if (pClientInfo->stage & FDFS_STORAGE_STAGE_DIO_THREAD) { pClientInfo->stage &= ~FDFS_STORAGE_STAGE_DIO_THREAD; } switch (pClientInfo->stage) { ... case FDFS_STORAGE_STAGE_NIO_RECV: pTask->offset = 0 ; remain_bytes = pClientInfo->total_length - \ pClientInfo->total_offset; if (remain_bytes > pTask->size) { pTask->length = pTask->size; } else { pTask->length = remain_bytes; } if (set_recv_event(pTask) == 0 ) { client_sock_read(pTask->event.fd, IOEVENT_READ, pTask); } result = 0 ; break ; case FDFS_STORAGE_STAGE_NIO_SEND: result = storage_send_add_event(pTask); break ; case FDFS_STORAGE_STAGE_NIO_CLOSE: result = EIO; break ; default : logError("file: " __FILE__", line: %d, " \ "invalid stage: %d" , __LINE__, \ pClientInfo->stage); result = EINVAL; break ; } if (result != 0 ) { add_to_deleted_list(pTask); } }
调用了client_sock_read函数进行处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 static void client_sock_read (int sock, short event, void *arg) { ... pTask->offset += bytes; if (pTask->offset >= pTask->length) { if (pClientInfo->total_offset + pTask->length >= \ pClientInfo->total_length) { pClientInfo->stage = FDFS_STORAGE_STAGE_NIO_SEND; pTask->req_count++; } if (pClientInfo->total_offset == 0 ) { pClientInfo->total_offset = pTask->length; storage_deal_task(pTask); } else { pClientInfo->total_offset += pTask->length; storage_dio_queue_push(pTask); } return ; } return ; }
数据包的网络接收和磁盘的处理成为一个环,接收完一部分,通过队列压入磁盘队列,磁盘线程处理完以后又通过像工作线程的fd进行写,触发网络线程读取这个task。自此源源不断将数据传过来。
总结:
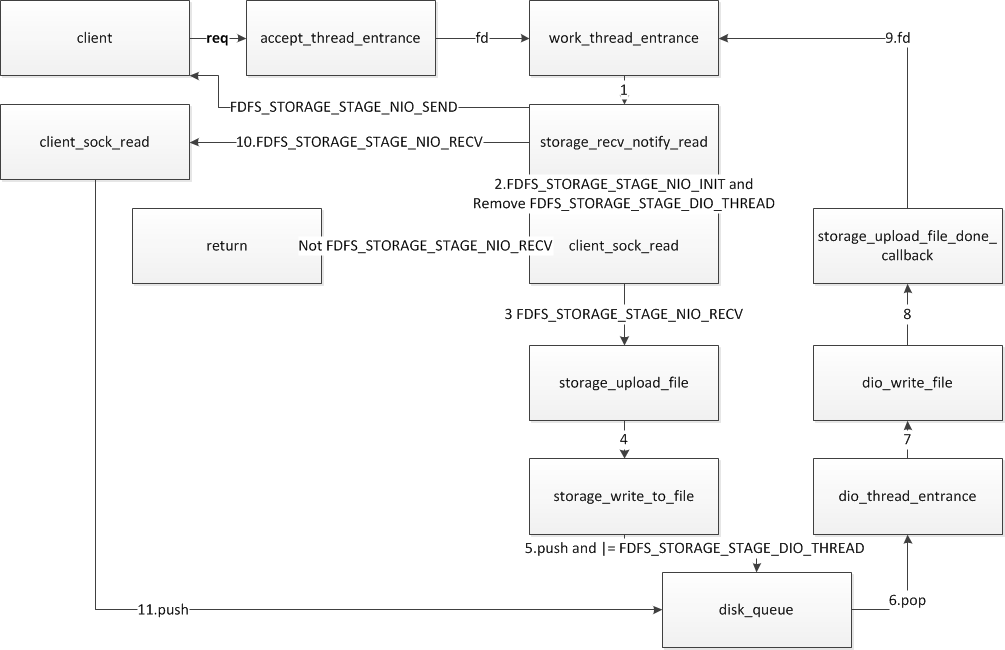
还是上图吧,整个处理流程如下图
fastdfs storage流程分析图
1 client发出请求,accept线程catch到描述符,初始化pTask结构,填入描述符,然后将pTask通过管道给work_entrance
2 进入storage_recv_notify_read函数
3 根据当前的pTask->stage等于FDFS_STORAGE_STAGE_INIT为fd创建读事件,绑定函数client_sock_read
4 调用storage_upload_file
5 storage_upload_file调用storage_write_to_file
6 storage_write_to_file调用压磁盘队列函数storage_dio_queue_push
7 storage_dio_queue_push将pTask->stage |= FDFS_STORAGE_STAGE_DIO_THREAD
8 根据事件触发机制,client_sock_read将被不断的调用,然而由于pTask->stage != FDFS_STORAGE_STAGE_RECV,所以返回
9 磁盘线程通过队列取pTask,调用pTask的处理函数dio_write_file
10 调用storage_upload_file_done_callback,调用storage_nio_notify,通过管道的形式将pTask压入工作进程
11 触发storage_recv_notify_read,将task->stage的FDFS_STORAGE_STAGE_DIO_THREAD标志去除
12 根据task->stage的FDFS_STORAGE_STAGE_RECV状态,调用函数client_sock_read
13 client_sock_read读取完以后调用磁盘队列函数storage_dio_queue_push
14 重复7
15 直到结束
一次上传逻辑分析完成
另外pTask的大小是在配置文件里指定的,默认256KB,补充说明一下
每个连接只提供一个pTask来做数据接受和写,猜测是怕大并发占用太多的系统内存吧。
比如1W并发下,256K的pTask大致是存在1W个,也就是2.5G左右内存
我以前自己写的那个分布式文件系统也是这个串行化的逻辑,因为这样开发简单有效。
有一点不足,我以前把数据压入磁盘IO后,我就删除了这个事件,等到磁盘线程读写完毕,我再建立这个事件。
看鱼大是通过判断pTask->stage的状态来暂时忽略回调的,这样在逻辑上比较好,毕竟有事件发生了就要去处理,删掉了始终不是什么好办法。
未完待续