关于redis集群线上以及测试环境出现read time out,connect time out的总结
time out这个问题是我刚实习的时候所有的业务组就都存在并且反应的。但是最近这段时间才定位了错误,固然这中间弄了小文件系统等等,但主要还是本人能力不太够导致的。
由于定位的时间拖得太长,导致大家对twemproxy-redis都有一种不稳定,不放心的看法,然而今天要为它正名:
代码没问题,一切都是网络不稳定惹的祸。
1 首先分析测试环境。
在测试组和同步业务的帮助下,我们拉来了device的数据进行测试(使用了ntpdate对所有机器进行了时间同步)
这个业务并发是不高的,每个key的value也相当的小,10多B罢了。然而在测试环境复现了read time out现象。随后我修改了proxy的代码,插入了log。

取460070000144258这个key。
在proxy上查到这个key记录

它的值是$1117800144258,符合redis协议没有问题。
Time 1的值是client请求传入proxy的时间,
Time 2的值是proxy使用nc_writev系统调用的时间
可以看到time1和time2的相差非常小,这已经算上了proxy和redis进行通讯的时间了
而后分析proxy上抓到的包,找到这个时间点的这个返回值的包。

从这里得到了56961端口
而后分析client上抓到的包

通过上下文的对比,确认这是同一个包,然而时间相差了3.1秒。
Redis配置的时候,标准配置超时时间是2秒,因此客户端报出read time out。
2 再来分析线上环境
线上环境有着测试环境无论如何也复现不出的connect time out,而且是24小时不间断毫无规律的报出的。
写了一个C-S测试程序,client部署jetty上,server部署proxy上,client每1秒10次connect server,server仅仅是死循环的accept。非常简单的逻辑。
跑了8小时,分析log。
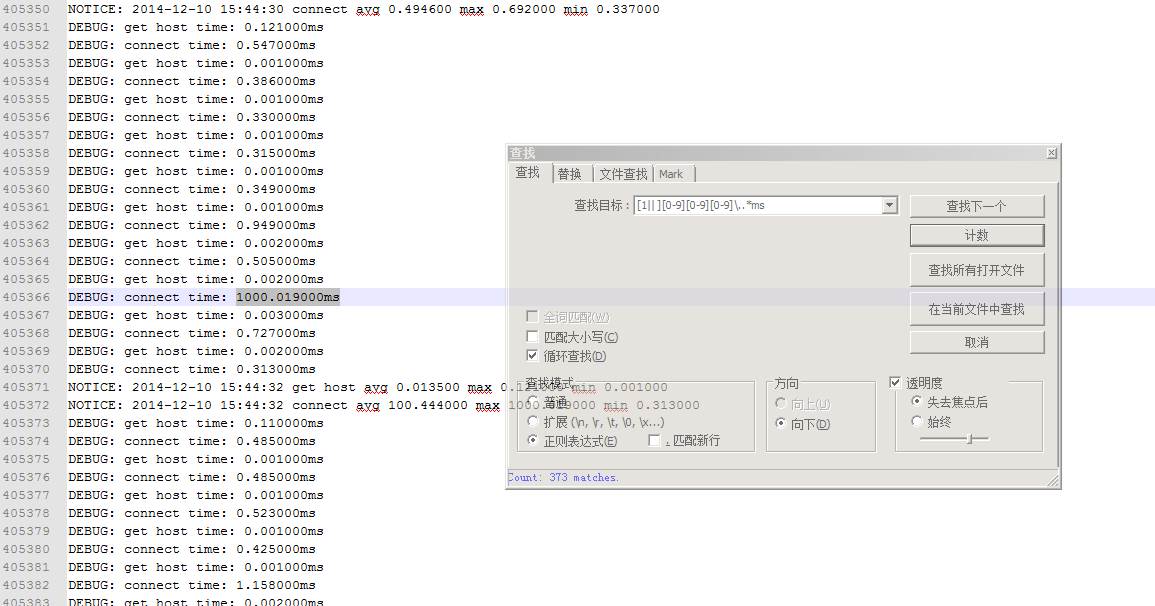
这373的match经过检查,都是1秒左右的,其中存在一个3秒左右的。
connect系统调用要这么久。深层去挖,要么是消耗在内核时间,要么是消耗在网络中了。
于是写程序来分析这一堆乱序重传的包,计算出sync,sync_ack,ack三次握手的耗时。
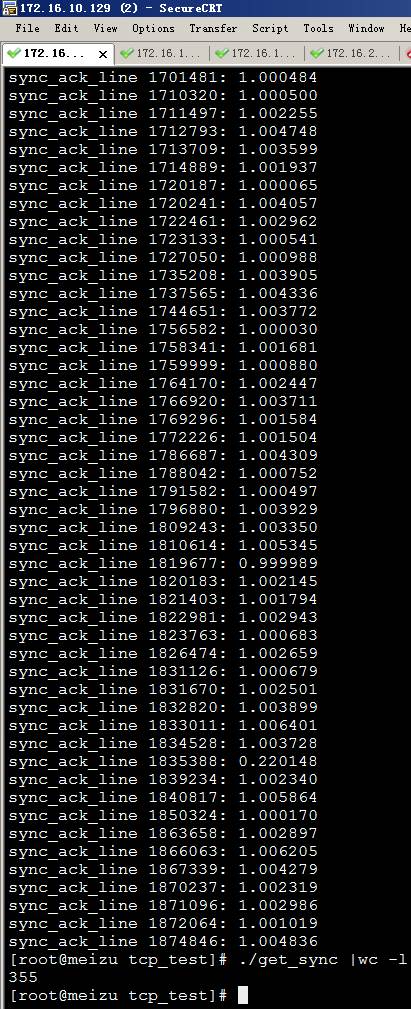
355个,比起373来少了18个,这18个都是丢包以后所以未检测到完整3次握手的包。
1 | 比如: |
相差两个小时,这已经是端口重用而不是重传范围的包了。
而这个包的sync_ack以及ack都不存在,证明三次握手某个环节丢包了。
另外通过ping –f指令,可以看到大量的”.”存在,再次印证线上网络的问题。
少量的connect都如此,何况大并发的情况下的网络。
总结:
一 测试环境的网络波动是可容忍范围内的,只是提给测试组的单,要注意对于敏感应用来说的网络不确定性
二 线上环境比测试环境还不稳定些,以下是我的建议:
运维:
运维的同学定位下能否解决网络的问题。
有两个点可以看看:
根据各个业务的反应,各台jetty报出time out的时间是相近的,这是什么原因
connect这里超时大部分都是1秒,这个1秒是否有什么原因
DBA: 目前read time out,connect time out暂时是无法消除的,而且每天出现的时间点和频度都不能确定,只能通过经验值来确定阀值,超过这个阀值说明业务故障(比如上周SYNC业务大量time out报错)。
业务:
大PV值的业务,如果time out过多影响了业务,可以尝试设大jedis-pool中timeout参数的值
后续追踪:
经过一周左右我和运维一起排查,确认是博通网卡虚拟化导致的延时,目前联系了供应商进行网卡驱动升级。
待续
-
2015-04-29
现象一:
昨天DBA反应线上存在某个redis slave 状态为down,反复重启无效
观察slave日志:
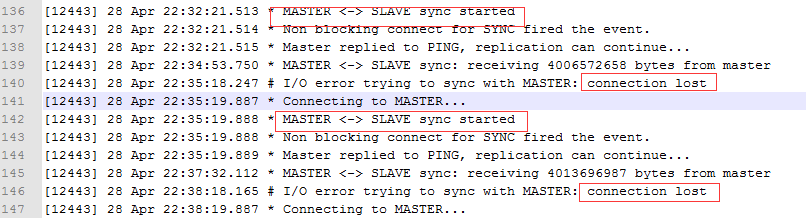
1 发现出现多次全同步,并且报出connect lost同步失败。