挖掘网络库中冷门而有趣的小知识
在维护网络库时,总能遇到一些没太大用处,但是很有意思的小知识,细细碎碎又不成体系,记录一下
异步的epoll使用
2015.5.22整理:
epoll下LT和ET的处理都是大致相同的
LT模式
读buff有数据 / 写buff有空间,就触发
ET模式
读buff有数据,且数据减少或调用epoll_mod时 / 写 buff 空间增加或调用epoll_mod时,才触发
LT模式例子:
https://www.cnblogs.com/lojunren/p/3856290.html
https://github.com/hurley25/ANet
https://juejin.im/post/5ab3c5acf265da2380598efa
https://www.zhihu.com/question/22840801
https://blog.codingnow.com/2012/04/mread.html
在ET模式中,需要主动把数据读完或者写满:
读处理是一直read
返回-1,检查errno,如果是EAGAIN那么不再读(缓冲区读完),如果是其他那么说明连接出错,进行报错然后也不再读。
返回0,说明对端关闭
返回大于0,成功读到数据
写处理是一直write,直到数据写完
返回-1,检查errno,如果是EAGAIN那么不再写(缓冲区写完),如果是其他那么说明连接出错,进行报错然后也不再写。
返回大于0,成功写数据
在使用tcp时,内核的tcp上存在读写缓冲区,上层app通过这个缓冲区来和实际的网络进行通信
app <=> 内核tcp <=> network
当读缓冲区有数据时,epoll就会通知READ就绪事件,让上层app去读,当应用一直不去读,就会导致接收窗口为0,通知发送方不要再发送了
当写缓冲区空闲时,epoll就会通知WRITE就绪事件,让上层app去写,当写满缓冲区,存在几个可能:
- 缓冲区不够大
- 本地拥塞窗口限制
- 就是刚才说的,对端应用层读太慢,接收窗口限制
因此当建立一条链接后,写事件总是就绪的,可以直接写入
tcp read < 0处理细节
在muduo库中,< 0直接被无视,根据https://github.com/chenshuo/muduo/issues/314的回答
read() 如果由于对方 RST 而返回 -1,那么这个 fd 会保持 readable 状态,下一次 read() 会返回 0,然后就走正常关闭连接的流程了。
但是在其他库中 < 0并且排除掉EAGAIN会直接关闭描述符
因此我认为muduo库应该是偷懒了,确实这种写法会简洁一些,但是性能也变差了
close fd时epoll是否需要remove
根据Is it necessary to deregister a socket from epoll before closing it?
中提到man epoll中Q6写到
Q6 Will closing a file descriptor cause it to be removed from all epoll sets automatically?
Q6 关闭文件描述符会自动从所有 epoll 集中移除吗?
A6 Yes, but be aware of the following point. A file descriptor is a reference to an open file description (see open(2)). Whenever a descriptor is duplicated via dup(2), dup2(2), fcntl(2) F_DUPFD, or fork(2), a new file descriptor referring to the same open file description is created. An open file description continues to exist until all file descriptors referring to it have been closed. A file descriptor is removed from an epoll set only after all the file descriptors referring to the underlying open file description have been closed (or before if the descriptor is explicitly removed using epoll_ctl(2) EPOLL_CTL_DEL). This means that even after a file descriptor that is part of an epoll set has been closed, events may be reported for that file descriptor if other file descriptors referring to the same underlying file description remain open.
A6 会,但是需要注意以下几点。文件描述符是指向打开的文件描述(参见 open(2))的引用。每当通过 dup(2)、dup2(2)、fcntl(2) F_DUPFD 或 fork(2) 复制描述符时,会创建一个新的文件描述符,指向同一个打开的文件描述。打开的文件描述将继续存在,直到指向它的所有文件描述符都被关闭。只有在所有关联到底层打开文件描述的文件描述符被关闭(或者在这之前明确地使用 epoll_ctl(2) EPOLL_CTL_DEL 移除)后,文件描述符才会从 epoll 集中移除。这意味着即使 epoll 集中的某个文件描述符已经被关闭,只要仍有其他文件描述符指向同一个底层的文件描述并保持打开,那么可能仍会报告该文件描述符的事件。
epoll源码流程
前置知识
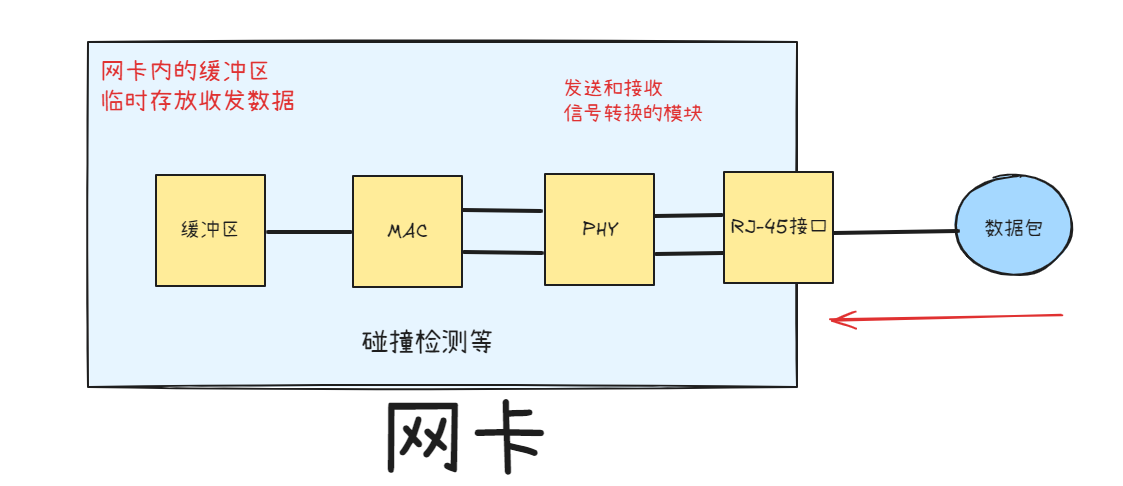
网卡DMA(Direct Memory Access)
直接内存访问,是一种在计算机中快速读写内存的技术。它允许硬件子系统(例如网卡)直接访问系统内存,而无需通过CPU进行数据传输。
在Linux网卡中,DMA被用于接收和发送数据。当网卡接收到数据时,它会使用DMA将数据直接写入系统内存,然后通知CPU数据已经可用。同样,当需要发送数据时,CPU会将数据写入一块内存区域,然后告诉网卡通过DMA从该内存区域读取数据并发送出去。这种方式可以大大提高数据传输的效率,因为CPU不需要参与每一个数据的传输,从而可以更好地专注于执行其他任务。
网卡RingBuffer
这个写入的内存叫做RingBuffer(环形缓冲区)
在网卡初始化的时候,会注册好DMA所需的内存RingBuffer,并初始化成一个固定长度。它的每个描述符在这里都代表了一个网络数据包,包含了该数据包的信息,如长度、起始地址等。当一个数据包被接收,网卡驱动程序会把这些信息填入一个描述符,并将其放入RingBuffer。
RingBuffer的读写操作是由两个指针来完成的,一个是生产者指针(写指针),一个是消费者指针(读指针)。当网卡接收到一个数据包并将其存入RingBuffer时,生产者指针就会通过原子操作向前移动一位。当内核从RingBuffer中取出一个数据包进行处理时,消费者指针就会通过原子操作向前移动一位。当生产者指针追赶上消费者指针时,说明RingBuffer已满,不能再存入新的数据包;反之,如果消费者指针追赶上生产者指针,说明RingBuffer已空,没有数据包可以取出。

PS:注意区分网卡自己的接收队列:
RingBuffer是属于内核的,如果太小导致丢包,可以通过参数改大。
网卡接收队列是网卡自己的数据结构,是网卡自己的缓冲区,如下图:
初始化
网卡初始化
通过实现pci_driver这个接口类,注册网卡的初始化接口probe,以e1000网卡为例:
https://elixir.bootlin.com/linux/v2.6.0/source/drivers/net/e1000/e1000_main.c#L255
1 | static struct pci_driver e1000_driver = { |
然后在probe内初始化了网卡设备数据接口,并且定义了打开关闭网卡的接口
https://elixir.bootlin.com/linux/v2.6.0/source/drivers/net/e1000/e1000_main.c#L356
1 | static int __devinit |
在类似ifconfig up的指令启动网卡后,会调用到网卡的xxx_open函数
注册网卡设备的poll函数
poll函数是在e1000硬中断处理程序中的处理函数
https://elixir.bootlin.com/linux/v2.6.0/source/drivers/net/e1000/e1000_main.c#L356
1 | static int __devinit |
注册DMA写入的RingBuffer
打开网卡e1000_open的时候,就会开始注册RingBuffer
https://elixir.bootlin.com/linux/v2.6.0/source/drivers/net/e1000/e1000_main.c#L690,以下代码省略了错误处理部分
1 | static int |
以e1000_setup_rx_resources为例看接收RingBuffer如何注册的
https://elixir.bootlin.com/linux/v2.6.0/source/drivers/net/e1000/e1000_main.c#L870
1 | static int |
至此RingBuffer申请好,并且注册进DMA了
注册硬中断
当DMA完成以后,就会硬中断来通知CPU取数据了,硬中断是在打开网卡e1000_open以后才开始注册的:
https://elixir.bootlin.com/linux/v2.6.0/source/drivers/net/e1000/e1000_main.c#L690
1 | static int |
https://elixir.bootlin.com/linux/v2.6.0/source/drivers/net/e1000/e1000_main.c#L255
1 | int |
所以后续DMA发起的硬中断,会让CPU执行e1000_intr
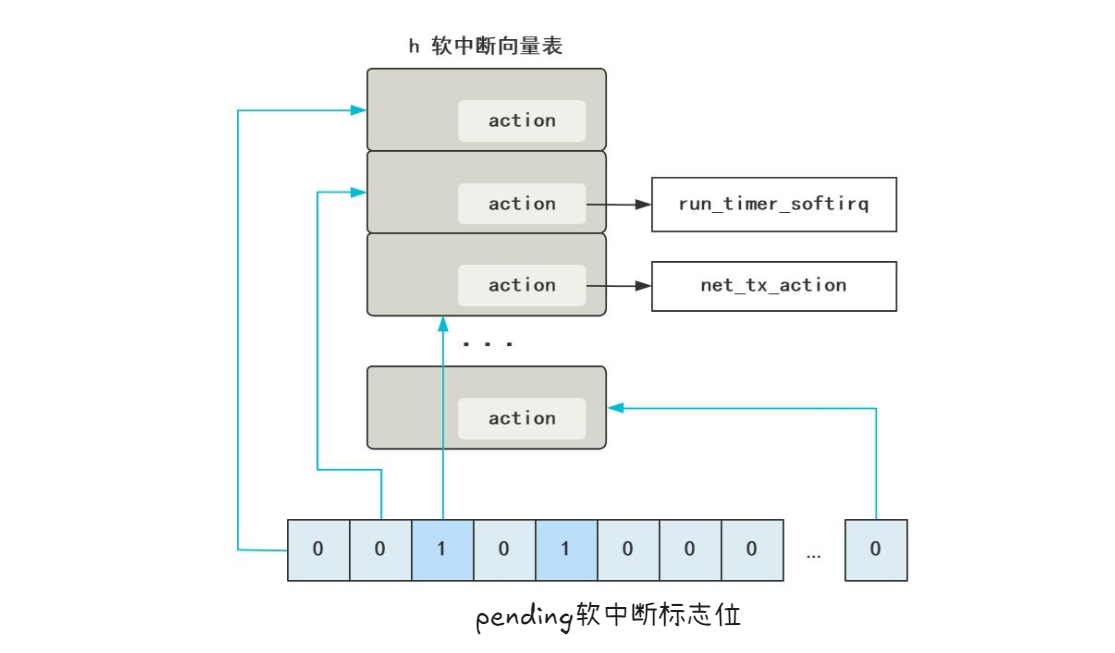
注册软中断
硬中断只能处理非常紧急的工作,所以一般是在在网卡硬中断响应程序把工作的下半部分放到软中断来执行。
每个CPU会绑定一个ksoftirqd内核线程专门用来处理软中断响应。2个 CPU 时,就会有 ksoftirqd/0 和 ksoftirqd/1这两个内核线程。
网卡接收到数据后,当DMA拷贝完成时,向CPU发出硬中断,这时哪个CPU上响应了这个硬中断,那么在网卡硬中断响应程序中发出的软中断请求也会在这个CPU绑定的ksoftirqd线程中响应。
软中断是通过__raise_softirq_irqoff(NET_RX_SOFTIRQ);发出的,NET_RX_SOFTIRQ是一个中断号,在这里注册的:
https://elixir.bootlin.com/linux/v2.6.0/source/net/core/dev.c#L2993
1 | static int __init net_dev_init(void) |
注册了软中断以后,触发了软中断,内核就会从软中断向量表中取出对应的函数去调用
协议栈初始化
注册IP处理
https://elixir.bootlin.com/linux/v2.6.0/source/net/ipv4/af_inet.c#L1095
1 | static int __init inet_init(void) |
ip_init的代码在这里:https://elixir.bootlin.com/linux/v2.6.0/source/net/ipv4/ip_output.c#L1308
1 | static struct packet_type ip_packet_type = { |
所以后续packet_type的变量,值为ip_packet_type的时候,就会进入ip_rcv逻辑
注册TCP/UDP处理
TCP/UDP等协议的注册是在网络模块的,回到刚才注册IP处理中的inet_init
https://elixir.bootlin.com/linux/v2.6.0/source/net/ipv4/af_inet.c#L1095
1 | static struct inet_protocol tcp_protocol = { |
所以当遇到IPPROTO_TCP协议的时候,就会进入tcp_protocol的处理函数tcp_v4_rcv
收包流程
网卡到IP协议处理
sequenceDiagram
participant 网卡
participant CPU
participant e1000 as drivers/net/e1000/e1000_main.c
participant netdevice as include/linux/netdevice.h
participant 软中断处理
participant dev as net/core/dev.c
participant ip_input as net/ipv4/ip_input.c
网卡 ->> 网卡 : DMA写RingBuffer
网卡 ->> CPU : RingBuffer内有新数据触发硬中断
CPU ->> e1000 : 调用注册的中断处理程序e1000_intr()
e1000 ->> netdevice : __netif_rx_schedule(dev)
netdevice ->> netdevice : 硬中断非常简单,大部分工作都在软中断中完成:<br>当前设备加入对应cpu的poll_list里面:<br>list_add_tail(&dev->poll_list, &__get_cpu_var(softnet_data).poll_list);
netdevice ->> 软中断处理 : 发起软中断:<br>__raise_softirq_irqoff(NET_RX_SOFTIRQ);
软中断处理 ->> dev : 获取当前核的队列:<br>struct softnet_data *queue<br> = &__get_cpu_var(softnet_data);
loop 对queue->poll_list的每一项struct net_device *dev
dev ->> e1000 : dev->poll(dev)<br>网卡设备的poll函数在初始化的时候注册为了e1000_clean
e1000 ->>+ e1000 : struct e1000_adapter *adapter = dev->priv<br>e1000_clean_rx_irq(adapter, ...)
loop RingBuffer内的每一个buffer_info = &adapter->rx_ring->buffer_info[i]
e1000 ->>+ dev : 这一步把RingBuffer的内存数据转换成内核需要的sk_buffer结构:<br>skb = buffer_info->skb<br>netif_receive_skb(skb)
dev ->>+ dev : struct packet_type *pt_prev的赋值略过<br>deliver_skb(skb, pt_prev)
dev ->>+ ip_input : pt_prev->func(skb, skb->dev, pt_prev)<br>这个func是协议栈初始化中注册IP处理时注册的<br>至此,进入IP协议处理逻辑
ip_input ->>- dev : return
dev ->>- dev : return
dev ->>- e1000: return
end
e1000 ->>- e1000 : return
endIP到TCP
sequenceDiagram
participant dev as net/core/dev.c
participant ip_input as net/ipv4/ip_input.c
participant route as net/ipv4/route.c
participant dst as include/net/dst.h
participant ip_input1 as net/ipv4/ip_input.c
participant tcp_ipv4 as net/ipv4/tcp_ipv4.c
dev ->>+ ip_input : pt_prev->func(skb, skb->dev, pt_prev)<br>这个func是协议栈初始化中注册IP处理时注册的<br>至此,进入IP协议处理逻辑ip_rcv
ip_input ->>+ ip_input : ip_rcv_finish(skb)
ip_input ->>+ route : struct net_device *dev = skb->dev<br>struct iphdr *iph = skb->nh.iph<br>ip_route_input(skb, iph->daddr, iph->saddr, iph->tos, dev)
route ->>+ route : ip_route_input_slow(skb, daddr, saddr, tos, dev)
route ->> route : 查询得到路由信息,存入res<br>struct fib_result res<br>fib_lookup(&res, ...)<br>struct rtable * rth<br>初始化rth信息省略
alt res.type == RTN_LOCAL
route ->> route : 设置回调为本地处理<br>rth->u.dst.input = ip_local_deliver
else
route ->> route : 设置回调为转发函数<br>rth->u.dst.input = ip_forward
end
route ->>- route : return
route ->>- ip_input : return
ip_input ->>+ dst : dst_input(skb)
dst ->>+ ip_input1 : skb->dst->input(skb)
alt 如果skb->dst->input == ip_local_deliver
ip_input1 ->>+ ip_input1 : ip_local_deliver_finish(skb)
ip_input1 ->> ip_input1 : int protocol = skb->nh.iph->protocol<br>掩码获取协议值:<br>hash = protocol & (MAX_INET_PROTOS - 1)<br>获取协议结构体<br>struct inet_protocol *ipprot = inet_protos[hash])
alt 如果是tcp协议
ip_input1 ->>+ tcp_ipv4 : ipprot->handler(skb)<br>这个handler是协议栈初始化中注册TCP处理时注册的<br>至此,进入TCP协议处理逻辑tcp_ip_rcv
tcp_ipv4 ->>- ip_input1 : return
end
ip_input1 ->>- ip_input1 : return
end
ip_input1 ->>- dst : return
dst ->>- ip_input : return
ip_input ->>- ip_input : return
ip_input ->>- dev : returnTCP
先放下刚才的tcp_ip_rcv的收包流程,想下某个阻塞读的进程,是如何阻塞的,然后再看是如何被tcp_ip_rcv唤醒的
前置
2.6.0版本不一致的地方
大致流程都是类似的,2.6.0会更精练,因此分析的这个版本,有一些细节的区别:
在2.6.0版本中通过struct socket *sock = SOCKET_I(file->f_dentry->d_inode);来从struct file找到struct socket
在2.6的稍高版本就通过struct socket *sock = file->private_data;来设置对应关系了,这样会更简单
初始化socket看recv的关键函数
1 | //https://elixir.bootlin.com/linux/v2.6.39/source/net/socket.c#L1085 |
其中sock_map_fd()执行完毕以后,struct socket和struct file的数据结构如下,其中的.poll = sock_poll比较重要,下面epoll_ctl把socket注册进epoll分析会用到:

而security_socket_create到inet_create的逻辑有些复杂,略过,只放一个根据AF_INET对应inet_create的图
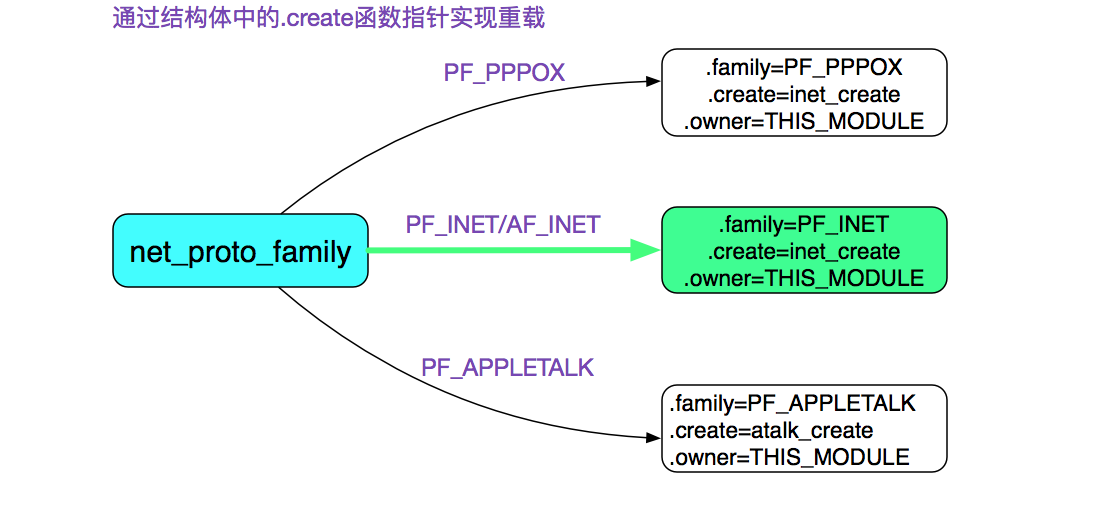
这个函数主要设置socket的关键回调函数:
https://elixir.bootlin.com/linux/v2.6.0/source/net/ipv4/af_inet.c#L324
1 | static struct inet_protosw inetsw_array[] = |
因此在SOCK_STREAM下回调如下
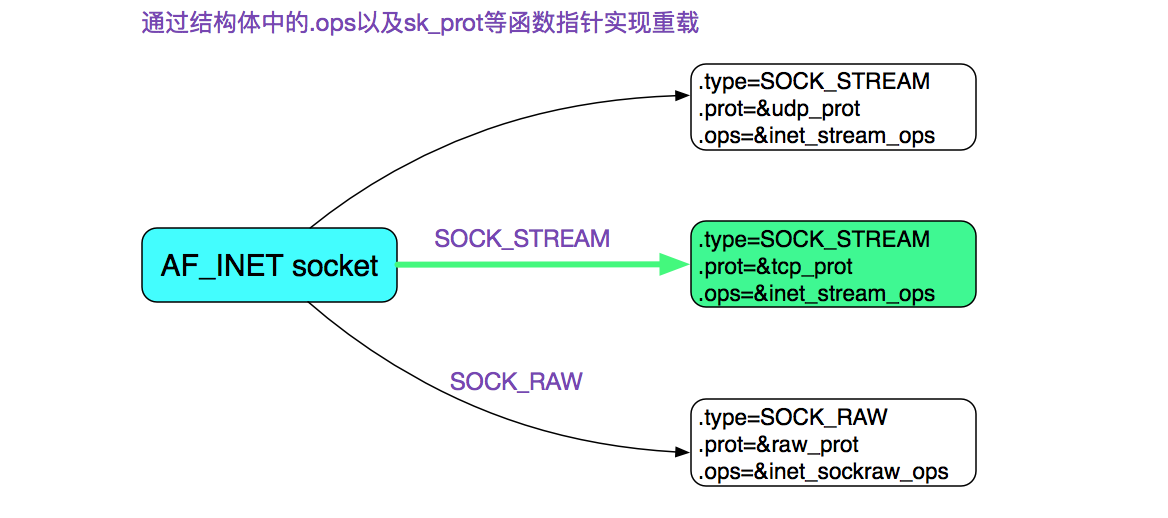
而tcp_prot和inet_stream_ops如下
1 | //https://elixir.bootlin.com/linux/v2.6.0/source/net/ipv4/af_inet.c#L885 |
即sock->ops->recvmsg = inet_recvmsg;
同时sock->sk->sk_prot->recvmsg = tcp_recvmsg;
这个两个回调下面进程阻塞recv流程会用到
进程阻塞recv流程
1 | socket.recv |
sock->ops->recvmsg 也就是inet_recvmsg,那么看inet_recvmsg的逻辑 https://elixir.bootlin.com/linux/v2.6.0/source/net/ipv4/af_inet.c#L733
1 | int inet_recvmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg, |
这里的recvmsg也就是tcp_recvmsg,tcp_recvmsg的逻辑很复杂,只关心核心的:什么时候阻塞,阻塞在什么变量上
https://elixir.bootlin.com/linux/v2.6.0/source/net/ipv4/tcp.c#L1500
1 | int tcp_recvmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg, |
https://elixir.bootlin.com/linux/v2.6.0/source/net/ipv4/tcp.c#L1378
1 | struct sock { |
这里DEFINE_WAIT是个宏,将当前进程存在了wait.task里面,并且设置了wait.func = autoremove_wake_function
https://elixir.bootlin.com/linux/v2.6.0/source/include/linux/wait.h#L248
1 |
autoremove_wake_function是调度模块中的一个唤醒函数,把传入的wait_queue_t结构,取出task进行唤醒,具体逻辑不深入了
回到刚才的问题:
什么时候阻塞?
在描述符设置为阻塞状态下,如果读不到期望数据,就阻塞
阻塞在什么上?
sk->sk_sleep上,这是
struct sock的一个等待链表表头wait_queue_head_t,这个下面会用到唤醒的时候,应该要从链表中取出第一项,然后调用它的回调函数autoremove_wake_function,就可以唤醒进程了
续接IP到TCP:收包唤醒阻塞recv的进程
所以回到收包流程上,应该唤醒sk->sk_sleep,就可以唤醒阻塞的进程了
sequenceDiagram
participant ip_input as net/ipv4/ip_input.c
participant tcp_ipv4 as net/ipv4/tcp_ipv4.c
participant sock as net/core/sock.c
participant sched as kernel/sched.c
ip_input ->>+ tcp_ipv4 : ipprot->handler(skb)<br>这个handler是协议栈初始化中注册TCP处理时注册的<br>至此,进入TCP协议处理逻辑tcp_ip_rcv
alt sk->sk_state == TCP_ESTABLISHED
tcp_ipv4 ->>+ tcp_ipv4 : tcp_rcv_established()
alt 序号正确TCP_SKB_CB(skb)->seq == tp->rcv_nxt && ack序号正确!after(TCP_SKB_CB(skb)->ack_seq, tp->snd_nxt) && 有数据len >= tcp_header_len
tcp_ipv4 ->> tcp_ipv4 : 更新期望接收的序号tcp_rcv_nxt_update(tp, TCP_SKB_CB(skb)->end_seq)<br>数据加入接收队列tcp_queue_rcv(sk, skb, tcp_header_len, &fragstolen)
tcp_ipv4 ->>+ sock : 唤醒用户进程有数据读取sk->sk_data_ready(sk)<br>这个函数指针在初始化socket的inet_create中赋值<br>实际指向sock_def_readable
sock ->>+ sock : wake_up_interruptible(sk->sk_sleep)
sock ->>+ sched : __wake_up(sk->sk_sleep,TASK_INTERRUPTIBLE, 1)
sched ->>+ sched : __wake_up_common(q, mode, nr_exclusive, 0)
loop wait_queue_t *curr = list_for_each_safe(tmp, next, &q->task_list)
sched ->> sched : curr->func(curr, mode, sync)<br>根据《进程阻塞recv流程》,这里func实际指向autoremove_wake_function
end
sched ->>- sched : return
sched ->>- sock : return
sock ->>- sock : return
sock ->>- tcp_ipv4 : return
end
tcp_ipv4 ->>- tcp_ipv4 : return
end
tcp_ipv4 ->>- ip_input : returnEpoll
epoll_ctl把socket注册进epoll
回顾一下epoll的用法
1 | int _max_connections = 1024; |
下面是epoll_ctl的流程图
sequenceDiagram
participant User
participant eventpoll as fs/eventpoll.c
participant socket as net/socket.c
participant tcp as net/ipv4/tcp.c
participant poll as include/linux/poll.h
User ->>+ eventpoll : sys_epoll_ctl(epfd, EPOLL_CTL_ADD, fd, ev)
eventpoll ->> eventpoll : struct epoll_event epds = *ev<br>从epfd转换成文件:struct file *file = fget(epfd)<br>fd转换成文件:struct file *tfile = fget(fd)<br>struct eventpoll *ep = file->private_data
alt op == EPOLL_CTL_ADD
eventpoll ->>+ eventpoll : ep_insert(ep, &epds, tfile, fd)
eventpoll ->> eventpoll : struct ep_pqueue epq<br>struct epitem *epi = EPI_MEM_ALLOC()<br>epq.epi = epi
eventpoll ->>+ poll : 设置poll调用回调<br>init_poll_funcptr(&epq.pt, ep_ptable_queue_proc)
poll ->> poll : epq.pt.qproc = ep_ptable_queue_proc
poll ->>- eventpoll : return
eventpoll ->>+ socket : tfile->f_op->poll(tfile, &epq.pt)<br>根据《初始化socket看recv的关键函数》<br>这里poll指向sock_poll()函数
socket ->> socket : struct socket *sock = SOCKET_I(tfile->f_dentry->d_inode)<br>2.6高版本这里sock = tfile->private_data
socket ->>+ tcp : poll_table * wait = &epq.pt<br>sock->ops->poll(tfile, sock, wait)<br>根据《初始化socket看recv的关键函数》<br>这里poll指向tcp_poll()函数
tcp ->>+ poll : 执行poll调用回调<br>poll_wait(tfile, sock->sk->sk_sleep, &epq.pt)
poll ->> poll : epq.pt.qproc(tfile, sock->sk->sk_sleep, &epq.pt)<br>根据上面指向ep_ptable_queue_proc()函数
poll ->>- tcp : return
tcp ->>- socket : return
socket ->>- eventpoll : return
eventpoll ->>- eventpoll : return
end
eventpoll ->>- User : return着重分析一下流程图的最后一部分ep_ptable_queue_proc(tfile, sock->sk->sk_sleep, &epq.pt)
https://elixir.bootlin.com/linux/v2.6.0/source/fs/eventpoll.c#L991
1 | struct eventpoll { |
进程阻塞epoll_wait
sys_epoll_wait只是个壳子,就不进行注释了
https://elixir.bootlin.com/linux/v2.6.0/source/fs/eventpoll.c#L646
1 | asmlinkage long sys_epoll_wait(int epfd, struct epoll_event __user *events, |
然后看ep_poll逻辑,https://elixir.bootlin.com/linux/v2.6.0/source/fs/eventpoll.c#L1559
1 | static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events, |
唤醒了以后,通过ep_events_transfer拷贝就绪的事件
https://elixir.bootlin.com/linux/v2.6.0/source/fs/eventpoll.c#L1530
1 | static int ep_events_transfer(struct eventpoll *ep, |
简单注释了一下ep_collect_ready_items, ep_send_events, ep_reinject_items这三个关键子函数
1 | //https://elixir.bootlin.com/linux/v2.6.0/source/fs/eventpoll.c#L1372 |
总的来说,如果就绪的描述符队列是空的,就把自己放到struct eventpoll *ep的等待队列wq里面,由epoll的机制来唤醒
ET模式下会清空就绪队列,LT模式不会
那么下面唤醒的就是唤醒ep->wq了
续接IP到TCP:收包唤醒阻塞在epoll_wait的进程
sequenceDiagram
participant ip_input as net/ipv4/ip_input.c
participant tcp_ipv4 as net/ipv4/tcp_ipv4.c
participant sock as net/core/sock.c
participant sched as kernel/sched.c
participant eventpoll as fs/eventpoll.c
ip_input ->>+ tcp_ipv4 : ipprot->handler(skb)<br>这个handler是协议栈初始化中注册TCP处理时注册的<br>至此,进入TCP协议处理逻辑tcp_ip_rcv
alt sk->sk_state == TCP_ESTABLISHED
tcp_ipv4 ->>+ tcp_ipv4 : tcp_rcv_established()
alt 序号正确TCP_SKB_CB(skb)->seq == tp->rcv_nxt && ack序号正确!after(TCP_SKB_CB(skb)->ack_seq, tp->snd_nxt) && 有数据len >= tcp_header_len
tcp_ipv4 ->> tcp_ipv4 : 更新期望接收的序号tcp_rcv_nxt_update(tp, TCP_SKB_CB(skb)->end_seq)<br>数据加入接收队列tcp_queue_rcv(sk, skb, tcp_header_len, &fragstolen)
tcp_ipv4 ->>+ sock : 唤醒用户进程有数据读取sk->sk_data_ready(sk)<br>这个函数指针在初始化socket的inet_create中赋值<br>实际指向sock_def_readable
sock ->>+ sock : wake_up_interruptible(sk->sk_sleep)
sock ->>+ sched : __wake_up(sk->sk_sleep,TASK_INTERRUPTIBLE, 1)
sched ->>+ sched : __wake_up_common(q, mode, nr_exclusive, 0)
loop wait_queue_t *curr = list_for_each_safe(tmp, next, &q->task_list)
sched ->>+ eventpoll : curr->func(curr, mode, sync)<br>这个函数指针在《epoll_ctl把socket注册进epoll》中赋值<br>实际指向ep_poll_callback
eventpoll ->> eventpoll : 通过container_of拿到epitem:<br>struct epitem *epi = EP_ITEM_FROM_WAIT(wait)<br>根据epi拿到eventpoll:<br>struct eventpoll *ep = epi->ep<br>把当前epi加入eventpoll的就绪队列中:<br>list_add_tail(&epi->rdllink, &ep->rdllist)<br>唤醒eventpoll中的第一个等待项:<br>wake_up(&ep->wq)
eventpoll ->>- sched : return
end
sched ->>- sched : return
sched ->>- sock : return
sock ->>- sock : return
sock ->>- tcp_ipv4 : return
end
tcp_ipv4 ->>- tcp_ipv4 : return
end
tcp_ipv4 ->>- ip_input : return参考资料
-
这一篇不太准确,把RingBuffer和sk_buffer混淆了,认为DMA写入的是sk_buffer
- Post not found: from-netty-to-linux-tcp
主要是梳理的这一篇转载的文章
-
这一篇主要分析的tcp_rcv_established流程
-
这一篇主要是讨论进程阻塞recv和唤醒阻塞recv进程的流程的,有图很细致
https://blog.csdn.net/cloud323/article/details/130148735
tcp发包
主要是参考这一篇Linux操作系统学习笔记(二十二)网络通信之发包
flowchart TB
套接字层 --> 传输层TCP处理 --> 网络层IP处理 --> 链路层邻居子系统 --> 链路层网络设备子系统
subgraph 套接字层
direction LR
1.write --> 2.sock_write_iter --> 3.sock_sendmsg --> 4.inet_sendmsg --> 5.进入下一层tcp_sendmsg
end
subgraph 传输层TCP处理
direction LR
1.tcp_sendmsg --> 2.tcp_write_xmit
2.tcp_write_xmit --> 3.拥塞控制
2.tcp_write_xmit --> 4.滑动窗口
2.tcp_write_xmit --> 5.tcp_transmit_skb
5.tcp_transmit_skb --> 6.封装TCP头
5.tcp_transmit_skb --> 7.进入下一层ip_queue_xmit
end
subgraph 网络层IP处理
direction LR
1.ip_queue_xmit --> 2.ip_route_output_ports
2.ip_route_output_ports --> 3.fib_lookup --> 4.路由查找
2.ip_route_output_ports --> 5.封装IP头
2.ip_route_output_ports --> 6.ip_local_out
6.ip_local_out --> 7.ip_tables的NF_INET_LOCAL_OUT
6.ip_local_out --> 8.dst_output --> 9.ip_output --> 10.ip_finish_output --> 11.进入下一层__neigh_lookup_noref
10.ip_finish_output --> 12.进入下一层neigh_output
end
subgraph 链路层邻居子系统
direction LR
1.__neigh_lookup_noref --> 2.__neigh_create --> 3.arp_constructor
4.neigh_output --> 5.neigh_resolve_output --> 6.neigh_event_send --> 7.neigh_probe --> 8.arp_send_dst
4.neigh_output --> 9.进入下一层dev_queue_xmit
end
subgraph 链路层网络设备子系统
direction LR
1.dev_queue_xmit --> 2.__dev_xmit_skb[2.__dev_xmit_skb流控] --> 3.__netif_reschedule --> 4.raise_softirq_irqoff[4.raise_softirq_irqoff(NET_TX_SOFTIRQ)] --> 5.net_tx_action --> 6.netdev_start_xmit --> 7.硬件发送
endTcpConnection为什么要用智能指针管理
muduo库的书中4.7节提到
在非阻塞网络编程中,我们常常要面临这样一种场景:从某个TCP连接A收到了一个request,程序开始处理这个request;处理可能要花一定的时间,为了避免耽误(阻塞)处理其他request,程序记住了发来request的 TCP连接,在某个线程池中处理这个请求;在处理完之后,会把 response 发回TCP连接A。但是,在处理request的过程中,客户端断开了TCP连接A,而另一个客户端刚好创建了新连接B。我们的程序不能只记住TCP连接A的文件描述符,而应该持有封装socket连接的TcpConnection对象,保证在处理request期间TCP连接A的文件描述符不会被关闭。或者持有TcpConnection对象的弱引用( weak_ptr ),这样能知道socket连接在处理request期间是否已经关闭了,fd=8的文件描述符到底是“前世”还是“今生”。
否则的话,l旧的TCP连接A一断开,TcpConnection对象销毁,关闭了旧的文件描述符(RAI),而且新连接B的socket文件描述符有可能等于之前断开的TCP连接(这是完全可能的,POSIX 要求每次新建文件描述符时选取当前最小的可用的整数)。当程序处理完旧连接的request 时,就有可能把 response '发给新的TCP连接B,造成串话。
为了应对这种情况,防止访问失效的对象或者发生网络串话,muduo使用shared_ptr来管理TcpConnection 的生命期。这是唯一一个采用引用计数方式管理生命期的对象。如果不用shared_ptr,我想不出其他安全且高效的办法来管理多线程网络服务端程序中的并发连接。
书中提到的例子是TcpConnection被转发到了一个业务线程池中去完成,因此引入了多线程问题,需要用智能指针来解决生命周期问题,这个概念其实不好理解,muduo库书中的实现本身是单线程的
我在引入协程的时候,发现用协程视角去解读更好
1 | CoTcpConnection::Read(...) { |
从协程角度来看,在主协程AsyncRead读到 < 0的时候,就会要求Server或者Client删除持有的TcpConnection
但是这个时候另外一个协程还持有了TcpConnection,如果Server和Client不使用智能指针直接析构,会导致其他协程core掉
为什么Muduo TcpConnection 没有提供 close,而只提供 shutdown
这么做是为了收发数据的完整性。
TCP 是一个全双工协议,同一个文件描述符既可读又可写, shutdownWrite() 关闭了“写”方向的连接,保留了“读”方向,这称为 TCP half-close。如果直接 close(socket_fd),那么 socket_fd 就不能读或写了。
用 shutdown 而不用 close 的效果是,如果对方已经发送了数据,这些数据还“在路上”,那么 muduo 不会漏收这些数据。换句话说,muduo 在 TCP 这一层面解决了“当你打算关闭网络连接的时候,如何得知对方有没有发了一些数据而你还没有收到?”这一问题。当然,这个问题也可以在上面的协议层解决,双方商量好不再互发数据,就可以直接断开连接。
等于说 muduo 把“主动关闭连接”这件事情分成两步来做,如果要主动关闭连接,它会先关本地“写”端,等对方关闭之后,再关本地“读”端。练习:阅读代码,回答“如果被动关闭连接,muduo 的行为如何?” 提示:muduo 在 read() 返回 0 的时候会回调 connection callback,这样客户代码就知道对方断开连接了。
Muduo 这种关闭连接的方式对对方也有要求,那就是对方 read() 到 0 字节之后会主动关闭连接(无论 shutdownWrite() 还是 close()),一般的网络程序都会这样,不是什么问题。当然,这么做有一个潜在的安全漏洞,万一对方故意不不关,那么 muduo 的连接就一直半开着,消耗系统资源。
完整的流程是:我们发完了数据,于是 shutdownWrite,发送 TCP FIN 分节,对方会读到 0 字节,然后对方通常会关闭连接,这样 muduo 会读到 0 字节,然后 muduo 关闭连接。(思考题,在 shutdown() 之后,muduo 回调 connection callback 的时间间隔大约是一个 round-trip time,为什么?)
另外,如果有必要,对方可以在 read() 返回 0 之后继续发送数据,这是直接利用了 half-close TCP 连接。muduo 会收到这些数据,通过 message callback 通知客户代码。
那么 muduo 什么时候真正 close socket 呢?在 TcpConnection 对象析构的时候。TcpConnection 持有一个 Socket 对象,Socket 是一个 RAII handler,它的析构函数会 close(sockfd_)。这样,如果发生 TcpConnection 对象泄漏,那么我们从 /proc/pid/fd/ 就能找到没有关闭的文件描述符,便于查错。
muduo 在 read() 返回 0 的时候会回调 connection callback,然后把 TcpConnection 的引用计数减一,如果 TcpConnection 的引用计数降到零,它就会析构了。
一般的服务不会这么实现,是因为协议上已经约定了client在write,read后close的时机
另外一个原因是,在rpc服务来说,会复用tcp连接,无序的传输多个rpc请求的包,这种情况下一般不需要关闭连接,除非出错了需要整个close连接
没有Connect或者Bind的socket,可以触发epoll_wait
在分析tars源码的时候,发现在通知网络线程的时候,对没有实际连接到任何端点的描述符,有时候是EPOLLIN,有时候是EPOLLOUT,然后不需要读写。这样居然能唤醒网络线程?
这就超出我知识盲区了,我在自己的rpc框架中写过类似代码,但是是把管道加入了epoll中,对其读写来唤醒的
根据tc_epoller.h写了一下测试代码
1 |
|
编译运行
1 | root:~/tars/epoll_test# g++ -std=c++11 -g -Wall main.cpp tc_epoller.cpp -o out.exe -lpthread |
确实被唤醒了,读到了写入的数据100,唤醒的事件是16,也就是EPOLLHUP。
查了一下资料,即使对于阻塞模式下也确实如此Why am I getting the EPOLLHUP event on a brand new socket
See my other comment with the pastebin code. An uninitialized (i.e. before connect / listen) socket always seems to cause EPOLLHUP (at least when in blocking mode)
嗯,又学到了一手
非阻塞Connect必须通过getsockopt来检查是否连接成功吗
一些知名的开源库,客户端在connect()后总是通过getsockopt()来检查是否连接成功
例如redis
src/socket.c#L104 入口是为了连接在connSocketConnect为ae_handler回调创建epoll事件
1 | static int connSocketConnect(connection *conn, const char *addr, int port, const char *src_addr, |
src/socket.c#L402 ae_handler回调会设置成connSocketEventHandler
1 | .ae_handler = connSocketEventHandler, |
src/socket.c#L257 在epoll触发EPOLLOUT时,通过anetGetError检查连接状态
1 | static void connSocketEventHandler(struct aeEventLoop *el, int fd, void *clientData, int mask) |
1 | int anetGetError(int fd) { |
例如tars
在epoll_wait()中触发EPOLLOUT,这个事件分配给handleOutputImp(),在这里发送请求doRequest(),在正式发送请求之前会通过checkConnect()来检查是否连接上
util/src/tc_transceiver.cpp#L286
1 | void TC_Transceiver::checkConnect() |
例如nginx
sequenceDiagram
participant ngx_http_upstream_connect
participant ngx_event_connect_peer
participant epoll
participant ngx_http_upstream_send_request_handler
participant ngx_http_upstream_send_request
ngx_http_upstream_connect ->>+ ngx_event_connect_peer : rc = ngx_event_connect_peer(&u->peer)
ngx_event_connect_peer ->> ngx_event_connect_peer : s = ngx_socket(pc->sockaddr->sa_family, type, 0)<br>bind(s, pc->local->sockaddr, pc->local->socklen)<br>rc = connect(s, pc->sockaddr, pc->socklen)
ngx_event_connect_peer ->>- ngx_http_upstream_connect : return rc
ngx_http_upstream_connect ->> ngx_http_upstream_connect : u->write_event_handler = ngx_http_upstream_send_request_handler
alt rc == NGX_ERROR
ngx_http_upstream_connect ->> ngx_http_upstream_connect : 失败,直接返回NGX_HTTP_INTERNAL_SERVER_ERROR<br>ngx_http_upstream_finalize_request(r, u, NGX_HTTP_INTERNAL_SERVER_ERROR)
else rc == NGX_OK,一次就connect成功
ngx_http_upstream_connect ->>+ ngx_http_upstream_send_request : ngx_http_upstream_send_request(r, u, 1);
ngx_http_upstream_send_request ->>+ ngx_http_upstream_test_connect : ngx_http_upstream_test_connect(c)
ngx_http_upstream_test_connect ->> ngx_http_upstream_test_connect : getsockopt(c->fd, SOL_SOCKET, SO_ERROR, (void *) &err, &len)
ngx_http_upstream_test_connect ->>- ngx_http_upstream_send_request : return
ngx_http_upstream_send_request ->>- ngx_http_upstream_send_request_handler : return
else rc == NGX_AGAIN
ngx_http_upstream_connect ->> ngx_http_upstream_connect : 加入超时等待epoll触发<br>ngx_add_timer(c->write, u->conf->connect_timeout);
loop epoll事件循环
epoll ->> ngx_http_upstream_send_request_handler : 触发写事件
ngx_http_upstream_send_request_handler ->>+ ngx_http_upstream_send_request : ngx_http_upstream_send_request(r, u, 1)
ngx_http_upstream_send_request ->>+ ngx_http_upstream_test_connect : ngx_http_upstream_test_connect(c)
ngx_http_upstream_test_connect ->> ngx_http_upstream_test_connect : getsockopt(c->fd, SOL_SOCKET, SO_ERROR, (void *) &err, &len)
ngx_http_upstream_test_connect ->>- ngx_http_upstream_send_request : return
ngx_http_upstream_send_request ->>- ngx_http_upstream_send_request_handler : return
end
endsrc/http/ngx_http_upstream.c#L1508
1 | static void |
src/event/ngx_event_connect.c#L21
1 | ngx_int_t |
src/http/ngx_http_upstream.c#L2292
1 | static void |
src/http/ngx_http_upstream.c#L2059
1 | static void |
src/http/ngx_http_upstream.c#L2743
1 | static ngx_int_t |
测试demo
由于开源项目都是这么实现的,所以我认为getsockopt()是必须项目
在没有connect()成功时,有可能产生EPOLLOUT的事件,需要通过getsockopt()检查一下有没有连接成功,才能write,否则直接write会导致失败
但是同事写的一个简单的http客户端,connect成功以后没有getsockopt()检查,也运行的很正常
因此我写了一个demo测试一下
python_http_server
1 | from http.server import BaseHTTPRequestHandler, HTTPServer |
8000端口添加1200ms延迟
1 | # 在lo设备上添加了一个新的队列规则(qdisc),类型为prio。prio类型的队列规则创建了一个具有3个带宽队列的优先级队列规则 |
基于epoll的简单http客户端
1 | //simple_epoll.cpp |
1 | ~# g++ -std=c++17 -g -Wall simple_epoll.cpp -o out.exe -lpthread |
测试连接失败
1 | ~# ./out.exe |
在connect()调用1200ms以后,由于对端拒绝触发EPOLLERR或EPOLLHUP,报错Connection refused
中间不会产生任何的虚假唤醒
测试连接成功
1 | ~# ./out.exe |
在connect()调用1200ms以后,触发EPOLLOUT事件,在这中间也不会触发任何事件,导致read()或者write()失败
结论
只要正确的使用epoll,那么EPOLLOUT事件是只有当描述符可写的时候才会触发的,因此getsockopt()检查是否出错,来判断是否连接成功并不是必须的
事实上,如果不正确的使用epoll,那么即使getsockopt()检查出没有错误,也不意味着连接成功,见下面这个例子
golang的bug
net: connect after polling initialization
1 | 20161 1406175892.180009 epoll_wait(4, <unfinished ...> |
goalng的这个版本在connect()之前,就把描述符加入了epoll,导致另外一个线程的epoll_wait()被虚假唤醒
在getsockopt()检查了没有任何错误以后(此时还在连接中,对端还未拒绝),就开始write()了(还在连接中因此返回了EAGAIN)
由于下一次write()不会再用getsockopt()检查错误,因此导致返回了"Connection refused"
常见连接状态
tcp的关闭连接已经是常识了,如果不太了解可以在这篇博文补充基本知识

很容易遇到的两个状态就是CLOSE_WAIT和TIME_WAIT
CLOSE_WAIT和FIN_WAIT2
前者从状态图就能看出来,CLOSE_WAIT是收到fin以后,应用层没有正确处理,调用close,导致没有发出FIN包,是程序bug导致的
对应的FIN_WAIT2就是主动发起方的状态,可以通过修改 /proc/sys/net/ipv4/tcp_fin_timeout 的值来设定这个状态的超时时间
TIME_WAIT
由于只要关闭连接就会出现,默认会持续60秒,这可能是最常见的状态了,当服务器上有大量连接,就很容易因为太多的TIME_WAIT导致没有端口可用
有两种办法可以解决:SO_REUSEADDR和SO_LINGER
SO_REUSEADDR
SO_REUSEADDR和SO_REUSEPORT可以重用这个地址和端口,这其实很危险
所以一般只有服务端accept的端口才会使用,这是因为服务端停止会close掉所有的连接,此时会造成很多的TIME_WAIT状态
必须使用SO_REUSEADDR和SO_REUSEPORT才能让服务端立刻重启
SO_LINGER
SO_LINGER要复杂很多,用法如下
1 | /* |
可以看到,linger存在两个属性,虽然是int,其实是bool的语义,含义如下:
| l_onoff | l_linger | closesocket行为 | 发送队列 | 底层行为 | 备注 |
|---|---|---|---|---|---|
| 零 | 忽略 | 立即返回 | 保持直至发送完成 | 系统接管套接字并保证将数据发送至对端 | 默认行为 |
| 非零 | 零 | 立即返回 | 立即放弃 | 直接发送RST包,自身立即复位,不用经过2MSL状态 | |
| 非零 | 非零 | 阻塞直到l_linger时间超时或数据发送完成 | 在超时时间段内保持尝试发送,若超时则立即放弃 | 超时则同第二种情况,若发送完成则皆大欢喜 | 套接字必须设置为阻塞 |
由于第三行是只有阻塞的描述符才可以使用的,所以除去默认行为以外,只有第二行的参数可以使用
在这种情况下,close会直接发送rst,让描述符直接进入CLOSED的最终状态,不会再产生TIME_WAIT
当没有数据想要发送时,直接发送RST就不会导致任何问题
对于ping-pong的一请求一回答的场合,客户端需要主动关闭连接就可以使用这种方式
服务端一般而言不会主动关闭连接,但是会在长连接空闲过久时关闭,此时也可以使用这种方式
Delay ACK 和 Nagle 算法
这篇描述的更细致:再多来点 TCP 吧:Delay ACK 和 Nagle 算法
我做一个总结
Delay ACK
Delay ACK假设如果收到一个包,那么应用层会需要对这个包做出回应,等一小段时间(默认200ms),应用层写入数据以后再一起返回,直到超时了,才回复ACK
这是通过在TCP segment设置ACK标记来实现的(FIN也可以同时设置这个标记,使得四次挥手实际上只需要三次)

关闭Delay Ack:
1 | int flag = 1; |
Delay Ack默认就是关闭的
Nagle 算法
Nagle算法是为了解决每次发送一点内容就立刻发送的话,20字节的IP头和20字节的TCP头太浪费的问题
简单来说,就是如果要发送的内容足够一个 MSS了,就立即发送。否则,每次收到对方的 ACK 才发送下一次数据
关闭办法:
1 | int flag = 1; |
这样可以关闭
Nagle踩坑
当在广域网使用Nagle时,很容易因为过长的rtt等待对方的ACK导致吞吐量下降
我朋友在跨国专线中使用kafka客户端时发现每个tcp包都间隔很久才发送

根据librdkafka的文档发现
socket.nagle.disable这个选项默认值是false,也就是默认开启了nagle算法
网上也能看到对这个选项的讨论
Optimizing Kafka producers for latency
甚至还有提交pull request尝试修复这个问题的Disable Nagle algorithm by default
但是最终没有合进主分支
Delay ACK + Nagle必踩坑
当A使用了Nagle算法,B打开了Delay ACK,
A的一大串内容的最后一段不到一个MSS包,需要等待对方ACK才发送时
B只是个接收方,不想发送任何内容,直到B的Delay ACK超时,这一次请求才完成
路由器和交换机
路由器存储了ARP表和路由表工作
交换机存储了MAC表工作
交换机
交换机是根据MAC地址转发数据帧的。

当PC0发送ARP数据包,交换机会把数据包发往PC0之外的所有主机,并在相应包中记录下相应Mac地址与接口数据。
当PC0向PC1发送一帧数据,从1口进到交换机。交换机收到帧后,根据帧中的目的MAC先查本地MAC表,没有查到应从哪个接口转发这个帧。
接着,交换机把这个帧的源MAC和接口1写入交换表中,并向除1以外的所有接口广播这个帧,PC2将此广播帧丢弃,因为目的地址不对。
PC1收下这个目的地址是自己MAC的数据,并回应数据包,此时交换机会把PC1的MAC和对应接口2写入表中。然后当PC0与PC1再次发送数据交换机可以根据目的MAC查表找出对应的接口,将数据包直接送达对应的主机。

路由器
当IP地址多了之后,需要划分子网,路由器的根本目标,就是解决跨子网IP之间的路由。
子网内路由
每个子网,有一个网关,相当于子网的总代理。所有的报文,需要进行这个 子网网关的 转发。
有了网关之后,A 在自己电脑里配置的一个网关 IP 地址,以便在发给不同子网的机器时,发给这个 网关IP 地址,由这个网关转发。

有了这个代理之后, 数据包的转发规则如下:
- 如果源 IP 与目的 IP 处于一个子网,直接将包通过交换机发出去。
- 如果源 IP 与目的 IP 不处于一个子网,就交给路由器去处理。
这个规则就是通过路由表来配置的,通过route指令可以查看路由表,例如主机10.252.3.1:
1 | ~ route -n |
| 字段 | 说明 |
|---|---|
| Destination | 目标网络地址(0.0.0.0=默认路由) |
| Gateway | 下一跳网关地址(0.0.0.0=直连网络,无需网关) |
| Genmask | 子网掩码(用于计算网络范围) |
| Flags | 路由标志:U=路由可用G=使用网关H=主机路由 |
| Metric | 路由优先级(数值越小优先级越高) |
| Iface | 数据包出口的网络接口 |
第一条路由(默认路由)
1
0.0.0.0/0 → 所有非本机直连网络的流量 → 通过网关 10.252.3.253 从 eth0 发出
第二条路由(本地子网路由)
1
10.252.0.0 子网掩码255.255.252.0 → 目标地址在此范围内的流量 → 直接通过 eth0 发送(无需网关)
范围用ipcalc计算
1
2
3
4
5
6
7
8
9
10~ ipcalc 10.252.0.0 255.255.252.0
Address: 10.252.0.0 00001010.11111100.000000 00.00000000
Netmask: 255.255.252.0 = 22 11111111.11111111.111111 00.00000000
Wildcard: 0.0.3.255 00000000.00000000.000000 11.11111111
=>
Network: 10.252.0.0/22 00001010.11111100.000000 00.00000000
HostMin: 10.252.0.1 00001010.11111100.000000 00.00000001
HostMax: 10.252.3.254 00001010.11111100.000000 11.11111110
Broadcast: 10.252.3.255 00001010.11111100.000000 11.11111111
Hosts/Net: 1022 Class A, Private InternetHostMin和Max指定了在这个范围内的IP都会走这一条规则
跨子网路由
为了知道收到的这个数据包,该从自己的哪个端口出去,路由器上一般会配置跨子网路由,例如:
1 | ~ route -n |
因此,目标IP地址为10.252.0.1 ~ 10.252.3.254的数据包发向端口eth0,而10.252.4.1 ~ 10.252.7.254的数据包发向端口eth1
其他的数据包就发往上级网关192.168.1.254的eth2
路由查找实测
https://cloud.tencent.com/developer/article/1875669
路由查找源码逻辑
IP层
__mkroute_output在tcp发包的ip_queue_xmit --> ip_route_output_ports --> fib_lookup --> 路由查找的流程结束以后,在封装IP头之前
ip_route_output_slow中先执行了fib_lookup,然后执行__mkroute_output
https://elixir.bootlin.com/linux/v2.6.39.4/source/net/ipv4/route.c#L2348
1 | static struct rtable *__mkroute_output(const struct fib_result *res, |
也即是假设向192.168.100.200发送地址,那么这个rt_gateway就设置为这个地址。明显地,如果这个地址和网卡地址不在同一个网段中,如果链路层直接向该地址发送报文是无法成功的,所以就需要通过网关,反过来说,如果目的地址和网卡地址在同一网段中,这个发送是合理的,而且是最优的,也就是点对点的直达方式。
如果路由表项中设置了网关的地址,那么就修正这个地址为网关的地址。
链路层
arp_bind_neighbour在tcp发包的__neigh_lookup_noref --> __neigh_create --> arp_constructor的流程结束以后,在neigh_output之前
用于将新创建的邻居项与对应的ARP协议操作绑定
https://elixir.bootlin.com/linux/v2.6.39.4/source/net/ipv4/arp.c#L521
1 | int arp_bind_neighbour(struct dst_entry *dst) |
这里出现了一个新的数据结构neighbour(邻居项):
- 定义:
neighbour是链路层的结构体,描述了“下一跳”的链路层信息。 - 内容:包含下一跳的 IP 地址、MAC 地址、状态(是否可达)、接口等。
- 作用:负责把数据包送到物理网络上的“下一个节点”,比如网关或目标主机。
- 举例:你访问的目标如果不在本地网段,
neighbour记录的就是网关的 MAC 地址。
那么这一段的逻辑,就是通过 arp_bind_neighbour,使用刚才赋值的 rt_gateway 作为 key 查找/创建 neighbour。
neighbour 的构造函数(如 arp_constructor)会初始化相关操作指针(比如 output 函数)。
小结
发送流程
- 应用层发起连接(如
tcp_v4_connect) - 数据包下发到 IP 层(如
ip_queue_xmit) - IP 层查找并设置dst_entry->rt_gateway,用于给链路层的neighbour封装
- 最终调用
neighbour->output(skb),由链路层完成实际帧的封装与发送。
发送报文时,目标 MAC 是网关的 MAC,目标 IP 还是原始目标 IP。
NAT转换
NAT转换一般是路由器的职责,但是从linux的角度来看,是iptables的职责,而他其实是Linux的Netfilter的hook点来实现的:
- NF_INET_PRE_ROUTING:网卡收到数据包后,进入协议栈解析完 IP 头,路由前。这里是DNAT的部分
- NF_INET_LOCAL_IN:路由判断目标为本机后,交付本地协议栈前。
- NF_INET_FORWARD:路由判断需要转发时,转发前。
- NF_INET_LOCAL_OUT:本地进程发起数据包后,完成上一节路由查找源码逻辑的路由查找以后,发往网络前。
- NF_INET_POST_ROUTING:所有出站数据包(本机或转发),路由决策后,发往网卡前。这里是SNAT的部分
flowchart TD
A[网卡收到数据包] --> B[NF_INET_PRE_ROUTING]
B --> C{路由判断}
C -->|目标是本机| D[NF_INET_LOCAL_IN]
D --> E[交付本地进程]
C -->|目标是其他主机| F[NF_INET_FORWARD]
F --> G[NF_INET_POST_ROUTING]
G --> H[发往网卡]
I[本地进程发起数据包] --> I1[路由查找:在路由表中寻找IP对应表项]
I1 --> J[NF_INET_LOCAL_OUT]
J --> K[NF_INET_POST_ROUTING]
K --> H三种常见的 NAT 类型:静态 NAT、动态 NAT、端口地址转换(Port Address Translation,PAT)
前两者是一对一的,而端口地址转换可以做到一对多,当内网多台设备(IP A/B)使用相同源端口访问同一外网IP:端口时
1 | 内网主机 A: 192.168.1.100:5000 → NAT → 公网IP:6000 → 目标 8.8.8.8:80 |
都可以基于iptables去配置的,
例如,将内部网络上的地址段 192.168.1.0/24 的流量通过外部网络接口 eth0 转发到外部网络上,并将外部网络上的公共 IP 地址 203.0.113.50 的端口 80 转发到内部服务器的私有 IP 地址 192.168.1.10 的端口 8080 上,可以使用以下命令:
1 | iptables -t nat -A POSTROUTING -s 192.168.1.0/24 -o eth0 -j MASQUERADE |
这里配置的MASQUERADE是一种动态SNAT:
假设有如下场景:
- 内网主机A:192.168.1.100:12345
- 外网服务器B:8.8.8.8:80
- 路由器公网IP:100.100.100.1
A访问B时,NAT设备会创建一条NAT表项,大致内容如下:
| 协议 | 内网源IP:端口 | 公网IP:端口 | 目标IP:端口 |
|---|---|---|---|
| TCP | 192.168.1.100:12345 | 100.100.100.1:54321 | 8.8.8.8:80 |
这样,当8.8.8.8:80回包到100.100.100.1:54321时,NAT设备查NAT表项,知道要转发给192.168.1.100:12345。
- NAT表项不是永久存在的。一般在连接关闭或一段时间无数据后会自动清除。
- 如果NAT表项丢失(如iptables重启、路由器重启),外部回包就无法正确转发到内网主机。
在Linux上可以用如下命令查看当前的NAT/连接跟踪表项:
1 | # 查看所有连接跟踪表项(包括NAT相关) |
参考资料
iptables是一个很复杂的东西,目前看到最好的中文资料还是这一篇:iptables详解
很多资料中,iptables的五链都有很多画的不对的
这一篇画的图也不错:深入浅出带你理解 iptables 原理!
路由全链路流程图
flowchart LR
%% 数据包流向 %%
客户端 --> 客户端路由器NAT --> 服务端路由器NAT --> 核心交换机 --> 服务器
subgraph 客户端
direction TB
C_L4[传输层 TCP<br/>设置TCP头,调用 ip_queue_xmit()] --> C_L3[网络层 IP<br/>查路由表<br/>设置 skb->dst (路由项)<br/>设置IP头部<br/>MTU检查与分片]
C_L3 --> C_L2_Neigh[链路层: 邻居子系统<br/>根据下一跳IP查ARP表<br/>无缓存→发送ARP请求<br/>设置MAC头部]
C_L2_Neigh --> C_L2_Dev[链路层: 网络设备子系统<br/>选择发送队列、数据包入队RingBuffer<br/>触发网卡DMA发送]
end
subgraph 客户端路由器NAT
direction TB
R_L1L2_in[网络设备驱动 Driver 接收DMA数据] --> R_L2[链路层<br/>校验以太网帧<br/>剥离MAC头]
R_L2 --> R_L3[网络层 IP处理<br/>路由表查找确定下一跳<br/>TTL检查减1<br/>iptables POSTROUTING链 SNAT转换(源IP私网→公网)]
R_L3 --> R_L2_Neigh[链路层: 邻居子系统<br/>根据下一跳IP查ARP表<br/>无缓存→发送ARP请求<br/>设置MAC头部]
R_L2_Neigh --> R_L2_Dev[链路层: 网络设备子系统<br/>选择发送队列、数据包入队RingBuffer<br/>触发网卡DMA发送]
end
subgraph 服务端路由器NAT
direction TB
SN_L1L2_in[网络设备驱动 Driver 接收DMA数据] --> SN_L2[链路层<br/>校验以太网帧<br/>剥离MAC头]
SN_L2 --> SN_L3[网络层 IP<br/>iptables PREROUTING链 (DNAT公网IP→私网IP)<br/>路由表查找确定下一跳<br/>TTL检查减1]
SN_L3 --> SN_L2_Neigh[链路层: 邻居子系统<br/>根据下一跳IP查ARP表<br/>无缓存→发送ARP请求<br/>设置MAC头部]
SN_L2_Neigh --> SN_L2_Dev[链路层: 网络设备子系统<br/>选择发送队列、数据包入队RingBuffer<br/>触发网卡DMA发送]
end
subgraph 核心交换机
direction TB
SW_L1L2_in[网络设备驱动 Driver 接收DMA数据] --> SW_L2[链路层 MAC学习与转发决策]
SW_L2 --> SW_L2_Dev[链路层: 网络设备子系统<br/>选择发送队列、数据包入队RingBuffer<br/>触发网卡DMA发送]
end
subgraph 服务器
direction TB
S_L1L2_in[网络设备驱动 Driver 接收DMA数据] --> S_L2[链路层<br/>校验以太网帧<br/>剥离MAC头]
S_L2 --> S_L3[网络层 IP INPUT链检查目标IP为本机]
S_L3 --> S_L4[传输层 TCP 处理数据包]
end