fastdfs和ceph对比
需求是图片,视频等文件的存储
属于少写多读的场合,修改操作较少。文件粒度是大小文件都有。
fastdfs
先谈谈fastdfs,我在公司已经应用了两年了,对他的基本特性比较熟悉,在这种场合下有这些优缺点
需求是图片,视频等文件的存储
属于少写多读的场合,修改操作较少。文件粒度是大小文件都有。
先谈谈fastdfs,我在公司已经应用了两年了,对他的基本特性比较熟悉,在这种场合下有这些优缺点
golang的http上传文件的实现细节严格遵循了multipart/form-data的RFC1867规范,细节网上已经分析了很多了
本篇只是讨论golang上如何使用官方库实现的框架
客户端上传很简单,利用"mime/multipart"官方库即可完成上传
可以看到这里上传文件时全部加载在内存的bodyBuf字符数组中,所以这里只是上传小文件,大文件这么上传会写爆内存
首先是轮子地址:
https://github.com/tedcy/fdfs_client
最近用go做项目,要用到fastdfs
看了下github上star最多的fastdfs go客户端https://github.com/weilaihui/fdfs_client,稍微看了下感觉不太好。
codis在迁移方案上下了不少功夫,我认为codis和twemproxy最大的区别之一是:
codis是面向slot的管理,而twemproxy只是面向redis后端的管理
codis迁移是由Topom结构体的SlotCreateAction方法开始的,这个方法也许叫做SlotMoveToGroupCreateAction更加容易让人理解
这个方法需要两个参数,slot id以及group id,目的是吧这个slot(以及该slot的所有key)迁移到目标group中
SlotCreateAction检测了一些边界条件,例如slot正在被迁移,或者该slot已经存在与目标group
记录下踩到的坑
一 接口
1 | package main |
对于demo1来说数组能够容纳下这一块数据,因此array2依然指向array1,array1被改为[1 3 4]
对于demo2来说array3底层的数组能够容纳下这一块数据,因此array4依然指向array3底层的数组,array3被改为[1,3]
codis3.0内置了ha方案(在3.0以前ha是独立项目)
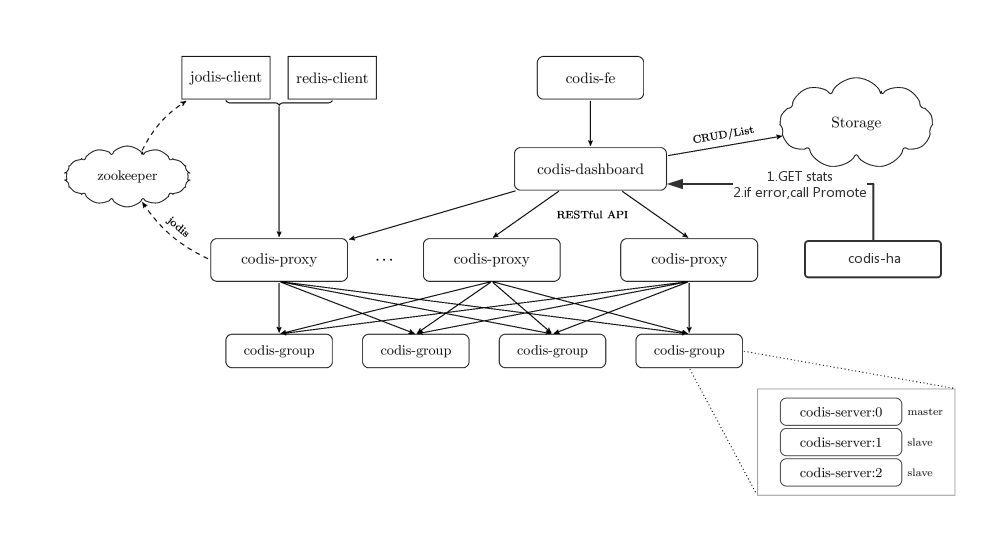
本文大致分析一下他的代码,试图找出他这样设计的目的,是否还存在什么缺点以及分析缺点的解决方案
本文的对象是对redis集群有一定经验,基本了解过codis方案的读者
最近出现了网络超时的问题要排查,大致按照如图思路去排查
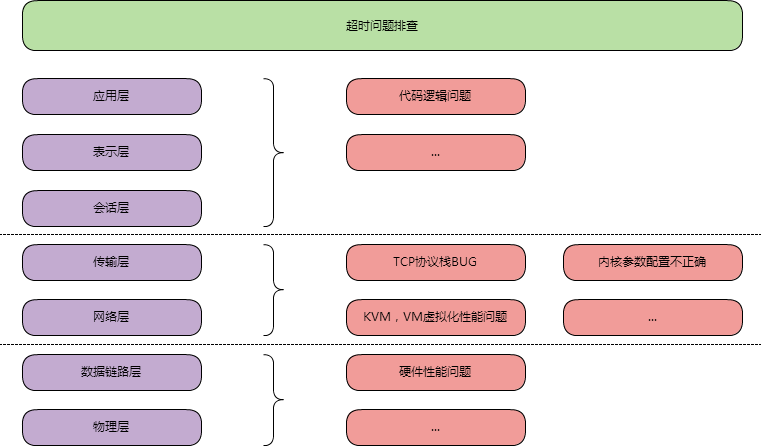
排除了代码逻辑问题,TCP相关可能的BUG,内核参数等问题后
在排查KVM问题时,在同一个宿主机的不同KVM上,复现了超时问题。
发现大部分异常连接时长都在1s左右,通过抓包分析,可以看到这部分的包被重传了,重传的时间固定为1秒。
zookeeper的库用起来很麻烦,建议使用我封装的zookeeper c库,能考虑更少的zookeeper本身的逻辑
链接:
在上一篇文章查CLOSE_WAIT泄漏问题的时候稍微看了下zookeeper c源码,大致对他的流程来做一个分析。
对于C/S模型而言,传统的请求和回复是这样的
1 | req -------------> |
而pipeline模式是这样的
1 | req1 -------------> |
pipeline模式下的客户端可以狂吐数据,而不用等待服务端回复,服务端会按顺序返回rsp。
为了提高代码质量,在同事的帮助下学习了如何使用gtest进行单元测试
1 首先从googlecode上下载gtest的源码(googlecode明年一月即将关闭不知道这个项目会何去何从呢)
解压后参考README文件进行编译
1 | GTEST_TARGET=googletest ./travis.sh |