(nginx源码系列二)--由读nginx源码想到的多进程下accept的处理方式
| nginx源码本来应该放在nginx源码学习这一块。但是考虑到多进程下accept的处理可以单独拿出来讨论。所以还是单独一篇博客会比较好。 | ||
| ## nginx的结构 | ||
| 简单提一下nginx的启动流程 | ||
| 核心文件当然是core/nginx.c,main函数就在这里。 | ||
| 而在main函数中,最重要的我认为是nginx_init_cycle和ngx_master_process_cycle这两个函数。前者负责解析配置文件,按配置文件进行配置初始化。后者将进入总事件循环中。 | ||
| 解析配置大致是按照nginx_init_cycle->ngx_conf_parse->ngx_conf_handler这样的顺序进行的,这里很重要是因为模块的配置命令函数都由这里来运行,并且设定了一系列回调来执行响应事件后的函数。nginx的模块化就是依赖这个。 | ||
| 而进入总事件循环大致是按照ngx_master_process_cycle->ngx_start_worker_processes->(fork)->ngx_worker_process_cycle->ngx_process_events_and_time->ngx_process_events(epoll时实际上就是ngx_epoll_process_events)->epoll_wait的顺序进行的。 | ||
| 从调用顺序就能看得出来nginx是master-worker这样的设计结构。 | ||
| master只是负责启动,监控worker。由worker来进行事件响应式的事件循环。 | ||
| ngx_process_events_and_timers函数基本流程是这样的:先判断accept锁是否闲置,闲置就占有该锁,然后运行ngx_process_events时,把epoll_wait收集到的活跃描述字组成事件分别放入ngx_posted_accept_events(假如占有了accept锁的话)和ngx_posted_events队列中。而后运行ngx_event_process_posted来调用这两个队列的回调。运行完ngx_posted_accept_events队列后就会释放accept锁,防止accept锁长时间被占用。这是为了提高高并发能力的。 | ||
| 由于将触发事件放入队列延后处理,这里就不得不提到nginx关于stale event的处理了。 | ||
| ### stale event | ||
| stale event在nginx中存在有两种,一种是由于某连接同时存在read事件和write事件。因此会按顺序先运行read事件回调后执行write回调,如果read回调因为出错而把描述符关闭,那么此时执行write事件回调就会出错。因此需要对stale event做处理。这种处理比较常见,在大多数的epoll构成的事件库中都能看到。 | ||
| 另外一种是主要存在于event cache中前一个对象可能使得后一个对象失效的场景。例如队列中存在事件A,B,C。如果C的fd是由于A的upstream产生的,那么当运行A回调出错时关闭C的连接后。如果B upstream执行了ngx_get_connection从连接池拿取连接时,很有可能就是使用了之前释放的那个连接。如果执行C的事件时,只是通过判断连接的fd是否被设置为-1。那么显然是无效的。这时就需要一种手段来解决stale event了。 | ||
| epoll给的建议是当释放一个描述符时,使用一个数据结构来存储这些描述符,这样就不会乱了。在这里也是适用的,相对的改成存储释放过的连接,或者把队列里的这个连接删除就行了。但是这样显然是低效的。涉及到操作最快也是O(nlgn)时间复杂度的。 | ||
| redis使用了一个mask标记位来处理。 | ||
|
||
| 此时将对fe->mask & mask & AE_READABLE以及fe->mask & mask & AE_WRITABLE判断,假如不同说明缓存的event已经过期了 | ||
| 另外当同时存在读事件和写事件时,通过rfired值,只会运行读事件的回调,防止读事件释放连接而使得写事件过期 | ||
| 可以看到,这种方式很清晰。 | ||
| 然而,nginx使用了非常精巧的一种办法去处理。它利用了内存对齐的一字节冗余信息来判断,节省空间。 | ||
| 在ngx_get_connection函数中,连接的读事件和写事件都对一个 instance变量取反。 | ||
| 而在ngx_epoll_add_event和ngx_epoll_add_connection函数中 | ||
c ee.data.ptr = (void *) ((uintptr_t) c | c->read->instance); |
||
| 由于连接的地址变量第一位始终为0,因此可以用来存储instance变量的值。 | ||
| 而后在ngx_epoll_process_events中,将会进行 | ||
c c->fd == -1 || rev->instance != instance |
||
| 这样的判断,如果一个连接的intance被两次取反以后,当然就会和一开始存储在epoll结构中的指针中的instance不同了。也就能判断出stale event了。 | ||
| 然而这里依然有两个点没有说明,举实例来说明吧。 | ||
| 例如队列中存在事件A,B,C,D,E。A事件会关闭E,B,C,D都是接受连接事件,但是B,C再刚获取到连接时都失败了,此时instance被两次取反,然后E接受连接成功了,fd不为-1,这时stale event就无法分辨了。但是这种情况不会出现,因为accept事件和其他事件是不同的队列,accept事件在一轮epoll后会优先执行。也就是说实际的执行顺序是B,C,D,A,E。因此这一点不需要担心。 | ||
| 另外一点是类似的,唯一的区别是此时B,C,D并非被动接受连接,而是主动发起连接,也就是使用upstream模块。我翻阅了代码的流程,这种情况理论上的确可能是会出现的。但是实际上不会出现。因为正常来说异步的connect调用会直接返回NGX_AGAIN。因此一次upstream后进行connect操作后立刻就会返回,在同一轮的epoll处理中没有机会去释放连接。 | ||
| 当然,第二点这种情况只是我个人的猜测,查阅了资料,并没有人对这种理论可能出现stale event做讨论。如果有人有更好的解读,那么请为我解惑。 | ||
| nginx关于大并发的tricks还是很多的,不过我还没全看完,后面会继续分析。不过我觉得这个应该是比较有意思的了。 | ||
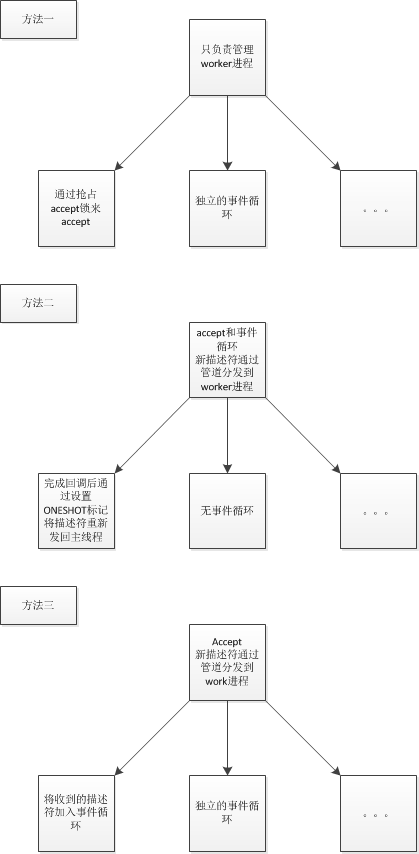
| ## 多进程下accept的处理方式 | ||
| 下面就聊聊我所知道的方式吧。这些方式都是主从结构的。 | ||
| 这些方法要解决的核心问题是如何在多进程/线程的情况下hold住更多的连接,这些都是半异步半同步模型变种的一种实际应用方式。 | ||
| 各个模型区别其实不是很大。当然我所读的开源项目较少,以后会继续完善这篇文章。 | ||
 |
||
| ### nginx方式 | ||
| master只是管理worker | ||
| 每个worker都可以accept,都有独立的事件循环,通过负载均衡锁(实质是共享内存)来实现各个进程的均衡。 | ||
| ### ONESHOT方式 | ||
| master进行epoll_wait且为唯一的事件循环,并且对listen的fd触发后进行accept。在add事件时加入EPOLLONESHOT标记,使得该描述符虽然加入epoll,但是在标记位没有被重置时只会触发一次。而后通过管道分发到worker线程 | ||
| worker线程实质是个线程池,在回调执行完毕后重置EPOLLONESHOT标记,以触发下一次事件。 | ||
| EPOLLONESHOT的使用,在我看来是由于事件循环和回调是异步处理而需要使用的,由于事件循环和回调异步,在不采取任何同步手段下,可能存在多个回调并行执行的可能,假如这些回调都是有状态的,例如下载时并未记录文件偏移量,而是靠回调的先后顺序来分别append在文件末尾。那么这样的过程就会出错。EPOLLONESHOT是epoll的同步手段。 | ||
| ### 我的方式 | ||
| 这种方式在我的分布式文件系统项目ydfs可以看到https://github.com/tedcy/ydfs | ||
| master是一个accept的死循环,同时管理worker线程。当描述符被accept到时,使用负载均衡算法选择管道数组中的一个压入accept到的描述符,这个管道的另一端是某个worker线程。 | ||
| worker线程的epoll_wait感知到管道的活跃,将描述符读出,加入该线程的事件循环,然后就欢快的run handle了。 |
小结
这三种方式各有优劣。
nginx方式的优点是多个进程进行accept,系统的最大吞吐量是和核数成正比(性能好百万也不在话下),缺点是当所有进程恰好handle耗时较长时,accept可能得不到处理。另外就是实现上需要使用一些手段,比如accept锁,事件缓存等等,而使用事件缓存就得考虑到stale event了。
ONESHOT方式是我在书上看到的理论方式,似乎没看到开源实现。(这个优点缺点不好说,汗)
我的方式优点很明显,accept是主线程,肯定是会不断的去接收连接的,accept事件会被第一优先级去处理,另外编程也容易些,省去了例如nginx或者ONESHOT这样的同步方式。缺点也很明显,吞吐量大可能会达到单核极限,单核不足以去处理。但是应对文件系统来说,不太可能会出现这样的并发量,因为这只是存储层,应用层或者中间件层进行调用时肯定会使用连接池技术。根据我的测试,这种方式在应对C10K以及C100K问题时还是游刃有余的。
未完待续
相关文章
-
2015-01-28
nginx真是博大精深,最近写fastdfs的动态缩略图模块,刚好能有时间研究下,真是满心欢喜。
学习主要是靠两本书,其他的稍微搜搜也就能解惑了。
《Nginx模块开发与架构解析》这个我看的电子PDF
《Nginx开发从入门到精通》这个有网页版本的,挺好的: