维护redis时的异常处理
现象一:
昨天DBA反应线上存在某个redis slave 状态为down,反复重启无效
观察slave日志:
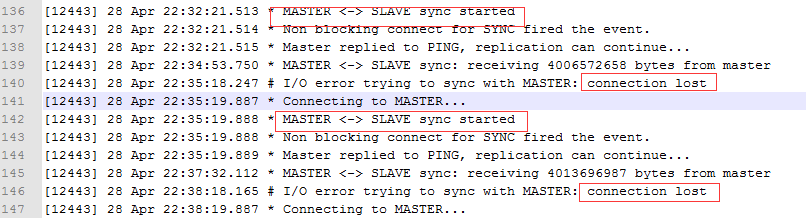
发现出现多次全同步,并且报出connect lost同步失败。
Master日志没有任何记录。
原因分析:
根据netstat显示的slave未出现timewait状态,判断是master主动关闭了连接
而master只有在缓冲区达到限制(默认的参数client-output-buffer-limit 256mb 64mb 60)后才会主动关闭连接。
原因是slave接受到master发送的rdb全量文件后,疯狂的往内存加载,此时slave会阻塞。
然后因为业务的change key频繁达到bgsave的触发瓶颈,master又进行数据增量同步,这些数据会放在client output buffer缓冲区内等待TCP发送
当这个缓冲区在60秒内有64MB大小,或者一下达到256MB,就会使得master立刻关闭该连接。
这是redis的自我保护机制。
应对方式:
平时可以在master执行 redis-cli client list指令,找那个cmd=sync,flag=S的client,注意OMem的变化。比这个值略大一些,来设置非常规情况的参数。

昨天晚上使用了config set参数将默认的slave 256mb 64mb 60改为512mb 256mb 300,而后重启slave进行观察
现象二:

同步成功
然而此时抛出第二个错误,no data nor PING received,而后居然又重新同步了。
原因分析:
昨天晚上也没想明白,后来操作fastdfs迁移也没空想了,直到刚才看了下代码
原来slave会每隔repl-ping-slave-period(默认10秒)ping master,如果超过repl-timeout(默认60秒)都没有响应,就会判定Master宕机。
如Master没挂但被阻塞住了也会报这个错。而后重连master。所以DBA会莫名其妙的发现slave老是进行全量同步。
应对方式:
此时可以通过config set指令在线适当调大repl-timeout。
未完待续
-
2014-12-19
time out这个问题是我刚实习的时候所有的业务组就都存在并且反应的。但是最近这段时间才定位了错误,固然这中间弄了小文件系统等等,但主要还是本人能力不太够导致的。
由于定位的时间拖得太长,导致大家对twemproxy-redis都有一种不稳定,不放心的看法,然而今天要为它正名:
代码没问题,一切都是网络不稳定惹的祸。
1 首先分析测试环境。
在测试组和同步业务的帮助下,我们拉来了device的数据进行测试(使用了ntpdate对所有机器进行了时间同步)