linux下超时重传时间(RTO)的实现探究
最近出现了网络超时的问题要排查,大致按照如图思路去排查
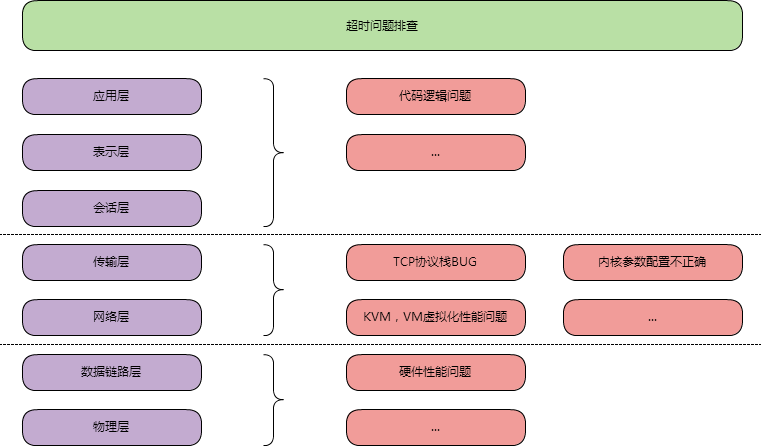
排除了代码逻辑问题,TCP相关可能的BUG,内核参数等问题后
在排查KVM问题时,在同一个宿主机的不同KVM上,复现了超时问题。
发现大部分异常连接时长都在1s左右,通过抓包分析,可以看到这部分的包被重传了,重传的时间固定为1秒。
这里重传时间为什么是1秒呢,相关的标准和实际实现是怎样的呢?
本文主要讨论的就是这部分内容(基于centos的2.6.32-358)
RFC标准
超时重传时间(RTO)是由当前网络状况(RTT),然后根据一个算法来决定。这部分相关内容《TCP/IP详解卷1》中有提到,但是已经过时了。
去RFC查了下,重传超时相关最新的是RFC6298,他更新了RFC1122并且废弃了RFC2988
稍微介绍一下其中内容,有兴趣的可以点进去看
1 重申了RTO的基本计算方法:
首先有个通过时钟得到的时间参数RTO_MIN
初始化:
\[RTO = 1\]
第一次计算:
\[SRTT = R\]
\[RTTVAR = R/2\]
\[RTO = SRTT + max(RTO\_MIN,4*RTTVAR)\]
以后的计算:
\[RTTVAL = 3/4 * RTTVAL + 1/4 * |SRTT - R'|\]
\[SRTT = 7/8 * SRTT + 1/8 * R'\]
\[RTO = SRTT + max(RTO\_MIN,4*RTTVAR)\]
RTO的最小值建议是1秒,最大值必须大于60秒
2 对于同一个包的多次重传,必须使用Karn算法,也就是刚才看到的双倍增长
另外RTT采样不能使用重传的包,除非开启了timestamps参数(利用该参数可以准确计算出RTT)
3 当4*RTTVAR趋向于0时,得到的值必须向RTO_MIN时间靠近
\[RTO = SRTT + max(RTO\_MIN,4*RTTVAR)\]
经验上时钟越准确越好,最好误差在100ms内
4 RTO计时器的管理
(1)发送数据(包括重传时),检查计时器是否启动,若没有则启动。当收到该数据的ACK时删除计时器
(2)使用RTO = RTO * 2的方式进行退避
(3)新的FALLBACK特性:当计时器在等待SYN报文时过期,且当前TCP实现使用了小于3秒的RTO,那么该连接对的RTO必须被重设为3秒,重设的RTO将用在正式数据的传输上(就是三次握手结束以后)
对linux的实际实现进行抓包分析
三次握手的syn包发送
1 | 01:00:00.129688 IP 172.16.3.14.1868 > 172.16.10.40.80: Flags [S], seq 3774079837, win 14600, options [mss 1460,nop,nop,sackOK,nop,wscale 7], length 0 |
从1秒起双倍递增
值得注意是实质上第五次超时以后等到第六次,才会通知上层连接超时,那一共是63秒
三次握手的syncak包发送
1 | 01:17:20.084839 IP 172.16.3.15.2535 > 172.16.3.14.80: Flags [S], seq 1297135388, win 14600, options [mss 1460,nop,nop,sackOK,nop,wscale 7], length 0 |
从1秒起双倍递增
正常的数据包发送
1 | 01:32:20.443757 IP 172.16.3.15.2548 > 172.16.3.14.80: Flags [P.], seq 3319667389:3319667400, ack 1233846614, win 115, length 11 |
从0.2秒起双倍递增,最大到120秒,一共15次
值得注意的是从32分开始,47分才结束,也就是15分钟25秒左右
linux是否支持了FALLBACK特性,做一个简单的测试
1 | server开启iptables后,client连接server,在5次超时次数内关闭iptables |
从这个测试中可以发现,当三次握手时RTT超过1秒时,数据发送阶段的RTO为3秒(服务端的SYNACK发生超时也是如此)
而后正常的一次RTT后,RTO重新收敛到200ms左右
再看看timestamps的支持如何
1 | server开启iptables后,client连接server,在5次超时次数内关闭iptables |
可以看到开启了timestamps后,FALLBACK机制重设RTO为3秒将不会起作用
linux的对RTO计算的微调
linux对RTO计算的实际实现和RFC文档相比还是有所出入的,如果只按照RFC文档去按图索骥,那么在实际的RTO估计上会误入歧途
1 根据上一段可以发现,他把RTO的最小值设为200ms(甚至在ubuntu上是50ms,而RFC建议1秒),最大值设置为120秒(RFC强制60秒以上)
2 根据我对linux代码的分析,在RTT剧烈抖动的情况下,linux的实现减轻了急剧改变的RTT干扰,使得RTO的趋势图更加平滑
这一点体现在两点微调上:
微调1
当满足以下条件时
\[|R'- SRTT| > RTTVAR\]
说明R'的波动太大了,和平滑过的RTT值比,差值的比RTTVAR还大
于是
\[RTTVAR' = 31/32RTTVAR + 1/32|R' - SRTT|\]
而RFC文档是
\[RTTVAR' = 3/4RTTVAR + 1/4|R' - SRTT|\]
可以看到,和RFC文档相比平滑系数乘以了1/8,表示R'对RTTVAR的影响将减小,使得RTTVAR更平滑,RTO也会更平滑
微调2
当RTTVAR减少的时候,会对RTTVAR做一次平滑处理,使得RTO不会下降的太离谱出现陡峭的趋势图
\[if(max(RTTVAR',RTO\_MIN) < RTTVAR)\]
\[RTTVAR'' = 3/4 * RTTVAR + 1/4 * max(RTTVAR',RTO\_MIN)\]
这里RTTVAR'指的是当前根据RTT计算得到的值,这个值限制了下限(RTO_MIN)以后和上一个RTT时的RTTVAR比较,当发现减少时,使用1/4系数来做平滑处理
这里为什么不对增大的情况做处理呢?我认为是因为RTO增大的话其实没事,但是如果减少量很大的话,可能会引起spurious retransmission(关于这个名词,详细见上文提到的RFC文档)
人为介入修改RTO的方法
回到最初的问题,是否能缩短RTO的值,而且这个RTO值如何根据linux的实际实现去预估
显然RTO初始值(包括FALLBACK)是不能改变的,这部分是固死写在代码里的
而三次握手以外的RTO值是可以预估的
预估时假设网络稳定,RTT始终不变为R(否则由于微调1和2,将极其复杂)
那么SRTT将始终为R,RTTVAR将始终为0.5R
\[if(RTO\_MIN < 4RTTVAR)\]
\[RTO = SRTT + RTO\_MIN = R + RTO\_MIN\]
否则
\[RTO = SRTT + 4RTTVAR = 3R\]
因此只需要改变RTO_MIN的值,就能显著影响RTO的值
RTO_MIN的设置
RTO_MIN的设置是根据ip route来实现的
1 | [root@localhost.localdomain ~]# ping www.baidu.com |
因为RTO_MIN < 2R,所以RTO = 3R = 27 * 3 = 81
如果是内网的话,RTT非常小
1 | [root@localhost.localdomain ~]# ip route add 172.16.3.16/32 via 172.16.3.1 rto_min 20 |
因为RTO_MIN > 2R,所以RTO = R + RTO_MIN = 1 + 20 = 21
如果对内网的整个网络有自信的话,也可以不设置目标IP,直接对全部连接生效,如下
1 | ip route change dev eth0 rto_min 20ms |
总结
1 linux的超时重传实现大体上参考了RFC,但是有一部分微调:
RFC只有一个RTO初始值,为1秒。而linux的实现将三次握手阶段的包的RTO设为1秒,其余包初始时间设为0.2秒
由于RFC规定的算法不够完美,linux的实际实现在RTT剧烈抖动的情况下,减轻了急剧改变的RTT干扰,使得RTO的趋势图更加平滑
2 连接的SYN重传时间,在除非重新编译内核的情况下是无法调整的,但是push包是可以调整重传时间的
3 在比较稳定的网络中,假设设置的rto最小值为RTO_MIN
\[if(RTO\_MIN > 2RTT),RTO = RTT + RTO\_MIN\]
\[if(RTO\_MIN < 2RTT),RTO = 3RTT\]
4 以移动网络客户端作为服务对象的服务器端,由于平均网络质量较差,调大RTO_MIN的值或许能减轻服务器的压力,具体值需要根据实际情况调整
5 在内网环境中,在KVM出现IO性能问题时,调小RTO_MIN的值或许能减少PUSH包的超时时间,但是会显著增加重传包的数目,可能会因为加重了KVM的负载反而使得情况恶化,所以具体值也需要根据实际情况调整
-
2015-07-30
经常能看到线上的服务器报出超时,除了自己代码的问题,因为网络环境导致超时的原因是各种各样的:
硬件上:各层交换机微突发;芯片转发;链路,网卡阻塞等等
软件上:在负载较高的情况下,KVM之类的虚拟化性能更不上(同一宿主机的两台KVM虚拟机压测时会报出大量超时);
网络导致的超时,简单的可以用ping -f来观察,但是有些细微的超时,需要借助更加细微的工具来发现
我遇到的网络问题,大部分情况下都能使用下面的代码测试验证