codis3.0高可用方案分析
codis3.0内置了ha方案(在3.0以前ha是独立项目)
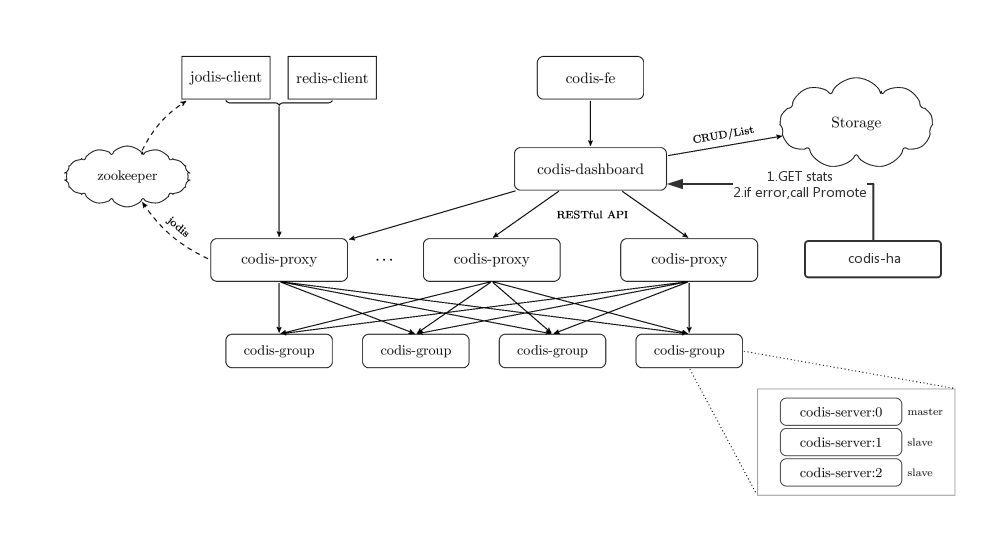
本文大致分析一下他的代码,试图找出他这样设计的目的,是否还存在什么缺点以及分析缺点的解决方案
本文的对象是对redis集群有一定经验,基本了解过codis方案的读者
HA代码
在cmd/ha下有ha的代码入口main.go
其中最重要的就是下面一段
1 | var lasthc *HealthyChecker |
newHealthyChecker的内容是通过dashboard的stat接口获取到HA对应集群的状态
LogProxyStats将记录下proxy的当前状态
LogGroupStats将记录下dashboard管理的所有codis-server的状态
Maintains就是实际的高可用策略了:
1 如果有proxy存在异常状态,那么不执行接下来的操作
2 遍历每个组的master,如果不处于SYNCED或者UNSYNC状态的(MISSING,ERROR,TIMEOUT,ALIVE),选取组中一台SYNCED状态的slave,对其执行promote指令,将其切换成主
分析:
1 灵活
HA组件完全利用dashboard提供的API进行高可用管理,这种方式非常灵活。可以自己选用是否需要HA支持。
2 出错的概率较小
以前参与过的redis集群HA方案是利用zookeeper做节点发现,每个redis-server都有一个watchdog组件来PING,并且将其对应的redis IP注册到zookeeper上响应group的路径上。
proxy会选择zk每个group路径下,序号最小的节点作为master(序号由zk api生成)来读写,因此master节点消失后,proxy会读写slave,同时该slave的watchdog会向slave发出SLAVE OF NO ONE来切换成master
这种方案看起来很美好,然而只要存在网络抖动,zk和watchdog的会话超时,就会发生误切。
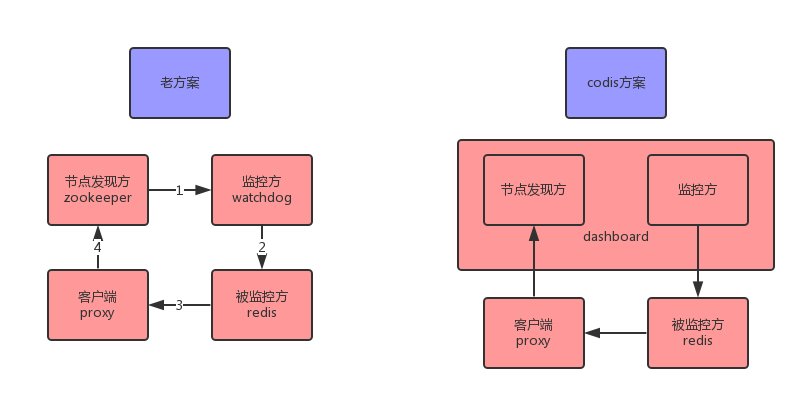
如图,老方案存在四个角色,节点发现方:zookeeper,监控方watchdog,被监控方redis,实际的通信客户端proxy。
而codis方案中,监控方和节点发行方是同一个(dashboard)。
可以看到,每一条箭头代表的网络不稳定都会出现问题
其中老方案存在四种较大的错误:
zookeeper和watchdog断线,其他线路正常,于是主从切换,属于误切
watchdog和redis断线,redis和proxy正常,于是主从切换,属于误切
watchdog和redis正常,redis和proxy断线,血崩
4)proxy和zookeeper断线,高可用方案失灵
codis方案避免了第一种错误,但是其他错误依然是存在的
3 分析下codis方案错误的解决方案
错误3基本是无法解决的。
对于错误2,4,如果把节点发现方,监控方和客户端同时集成于一体,是可以完全消除这些错误的,这样proxy就非常复杂了。
从实际部署上考虑的话
例如将dashboard和proxy尽量部署在同一个网段,同一个交换机甚至同一个宿主机。这样能尽量规避错误2
Promote指令
Promote指令由两个指令组成,Promote和PromoteCommit
promote需要指定组ID和被promote的ip地址,promoteCommit只需要指定组ID,这两个指令共同组成了promote指令
promote指令主要是一些边界条件的检测,例如组内正在执行promote或者正在进行slot迁移的话就直接返回了。检测完边界条件将进入Preparing状态
promoteCommit才是实际的重点,这部分代码在Topom结构体的GroupPromoteCommit方法中,将推动状态机,从Preparing状态往Prepared走
如图:
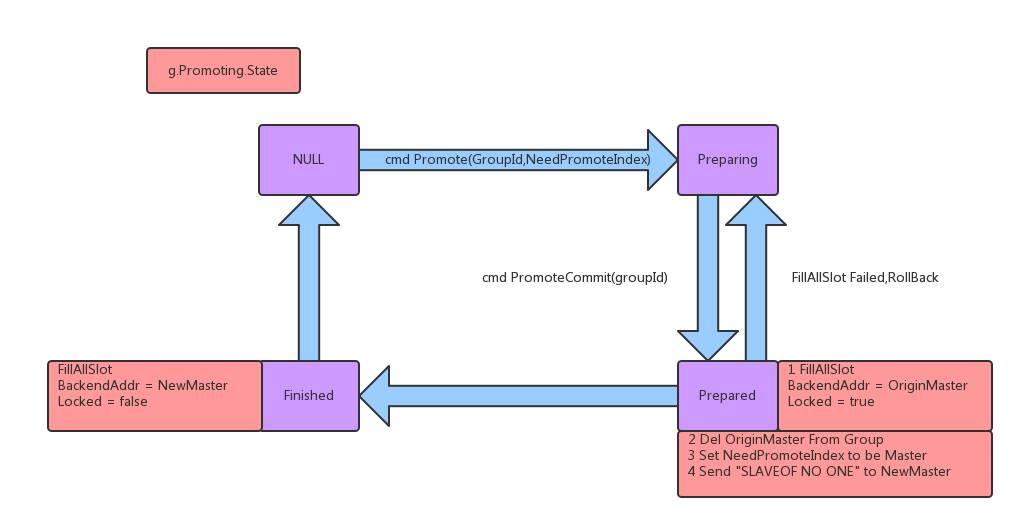
Prepared做的第一件事情是把该组相关的slot都锁死(fillslot函数来实现),假如存在失败,那么回滚到Preparing状态
而后把老的master从集群里删除,在组内标记master为被promote的slave,最后向该slave发出SLAVEOF NO ONE来真正提升为master
Prepared执行完毕后就变为Finished,这一步重新指定该组相关的slot的BackEnd为新的master,并且将slot全部解锁
这里说明下slot锁的作用
在proxy收到请求后会调用Route结构体的Dispatch方法,来指派请求分发到具体哪个slot
而后会调用Slot结构体的forward方法,来发送到具体哪个后端redis
在forward方法中会请求slot的读锁,而Promote指令调用的fillslot函数会请求slot的写锁
因此slot锁住以后,该slot不能进行任何的读写操作,请求该slot中的key将一直阻塞(可能有超时时间,这部分还没细看,但是根据测试30多秒还一直阻塞着)
分析
1 Promote指令分两段提交
这个我也没搞明白。。
2 Promote时为何要锁死redis对应的slot
在Promote指令发生的瞬间,其实就确认要放弃原来的master(不管是不是因为它挂了),所以不允许继续向原来的master读写,直到新的master准备完毕,而后才能继续进行请求
SyncCreateAction指令
将新的redis加入group是GroupAddServer指令,对codis-admin来说是以下指令
1 | codis-admin [-v] --dashboard=ADDR --group-add --gid=ID --addr=ADDR |
这之后如何和master建立主从链从而成为slave显然也是高可用的一部分
这部分用codis-admin或者在fe上可以完成
1 | codis-admin [-v] --dashboard=ADDR --sync-action --create --addr=ADDR |
这部分是Topom结构体的SyncCreateAction方法来开始的
SyncCreateAction只需要新的redis addr即可,最终目的是让该redis与他所在组的master建立主从关系
SyncCreateAction方法主要是检测一些边界条件,例如该组正在promote中或者发起过的SyncCreateAction方法正在后台被执行中
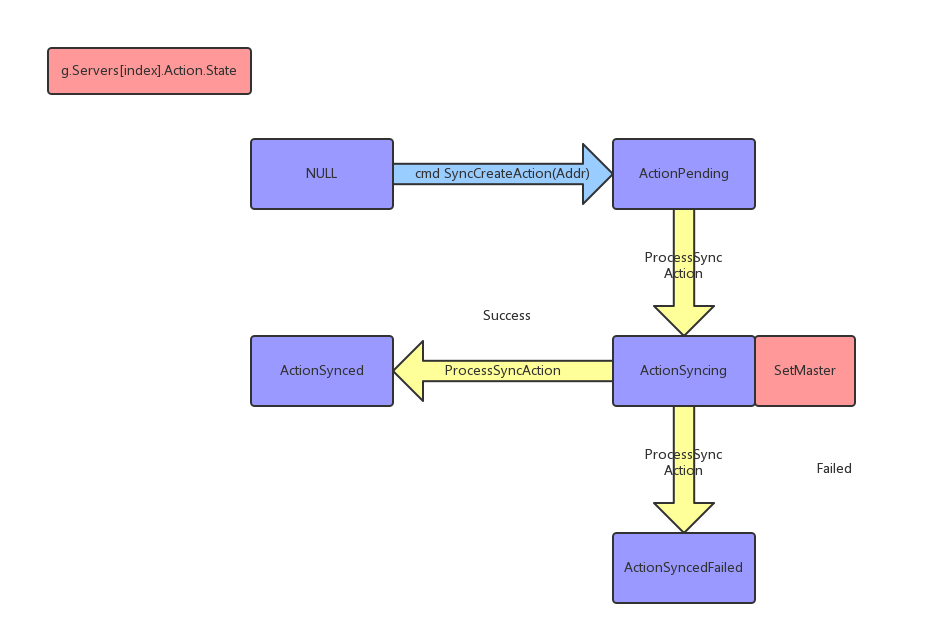
如图,通过SyncCreateAction进入ActionPending状态后,有个协程启动的后台函数ProcessSyncAction将推动状态机继续演化
进入Syncing状态后将对该redis发起SLAVE OF MASTER_ADDR的命令来创建主从连接
创建成功将进入ActionSynced状态,失败将进入SyncedFailed状态
分析
1 主从链建立要用状态机机制的原因
即使等待SLAVE OF响应时间很长,也可以丢到协程来做这个事情,为何要用状态机+后台进程的方式
我猜测是因为多个从同时进行主从同步将对同一个主造成较大压力
因此需要丢到一个队列中去依次进行
2 这一部分是否可以优化
基于上一个问题的猜测,因为每个组之间是互相不影响的,所以我认为可以给每个组一个状态机+后台进程
在很多组同时进行SyncCreateAction的时候将节省很多时间
特别是如果限定了一个组只有一个主和一个从的时候,完全可以干掉这个状态机和后台进程
在这种条件下,甚至可以把SyncCreateAction和GroupAddServer指令集成起来
Codis高可用方案的优化
结合k8s做到进一步的自动化,有几个细节可以优化
1 Promote指令里Prepared阶段,将master从组里剔除,此时应当尝试重启master。
实现方式是向该master发出SHUTDOWN NOSAVE命令,使redis进程退出,进程退出将导致pod退出,k8s感知到pod退出后将使master重启
由于docker容器启动只能使用一条阻塞指令
因此重启后如何重新加入该组(包括加入组和建立主从链),这个方案还在完善中
2 HA指令只管理了master的状态异常,如果slave状态异常应该尝试重启
实现方式是用命令SHUTDOWN该slave,而后就同上了