proc下meminfo的细节
续接十年前总结的前文linux的内存管理介绍
最近遇到了Serverless平台的管理节点上报内存不准确的问题,导致调度误判从而大量oom,所以不同于前文对meminfo一笔带过,需要对meminfo做一个系统的深入了解,并对其内容做一个分类,搞清楚存在的相互联系
首先贴一个/proc/meminfo的数据,可以看到,有49项,非常复杂
1 | MemTotal: 1950928 kB |
MemTotal,MemFree,MemAvailable
这个很常见,free -m也能看到
其中MemTotal不是真实的整机容量,使用dmest -T|grep reserved可以看到内核预留了一些容量
1 | Memory: 261120K/2013488K available (12292K kernel code, 2152K rwdata, 3852K rodata, 2408K init, 6468K bss, 93928K reserved, 0K cma-reserved) |
MemFree就是剩下完全没有使用的内存,但是并不是最终的可用内存,因为有一部分内存是可以page out的,所以有一个预估的MemAvailable
内核使用
前置知识
内存分配函数与内存黑洞
alloc_pages/__get_free_page:以页为单位分配,是全部内存分配的基础
kmalloc
以字节为单位分配虚拟地址连续的小块内存块
很接近我们使用的malloc,只是内核使用,所以有个k前缀
他是基于slab allocator的
slab
提供内存缓存管理,支持对象缓存功能,优化内存碎片,以提高内存重用性和性能
参见/proc/meminfo中的Slab/SReclaimable/SUnreclaim
vmalloc
以字节为单位分配虚拟地址连续的大块内存块
和kmalloc的区别就在于为了分配大块的内存块,把物理上不连续的页转换为虚拟地址空间上连续的页,必须专门建立页表项,而且因为它们物理上是不连续的,所以必须一个一个进行映射,这会导致比直接内存映射大得多的 TLB 抖动。尽管在某些情况下才需要物理上的连续内存块,但出于性能的考虑,很多内核代码都使用
kmalloc()。除非在不得已时才使用vmalloc(),比如动态装载模块时,需要获得大块内存。参见/proc/meminfo中的VmallocUsed 和 /proc/vmallocinfo
而alloc_pages作为一个非常底层的接口,是没有自动统计的,因此这一部分使用的内存会进入内存黑洞,这个无法追踪
Slab,SReclaimable,SUnreclaim
这个非常容易理解,Slab的总量,可回收的和不可回收的
VmallocTotal,VmallocUsed,VmallocChunk
出于性能原因,这些字段在 Linux 4.4 中被清零。与 glibc 链接的程序在启动时会读取此文件,并且它会造成可衡量的影响。
mm: get rid of 'vmalloc_info' from /proc/meminfo,Linux本人在本文说道
but the whole vmalloc information of of rather dubious value to begin with, and people who actually want to know what the situation is wrt the vmalloc area should just look at the much more complete /proc/vmallocinfo instead.
但整个 vmalloc 信息的价值一开始就相当可疑,而那些真正想知道 vmalloc 区域情况的人应该查看更完整的 /proc/vmallocinfo
vmallocinfo的信息数据如下,其中可以看到每个vmalloc的调用者:
1 | ~ grep vmalloc /proc/vmallocinfo |head |
所以统计vmalloc的使用量是:
1 | ~ grep vmalloc /proc/vmallocinfo | awk '{total+=$2}; END {print total}' |
没什么卵用的冷知识:lsmod第二列就是内核模块所占内存的大小,但是是按page算的,1个字节也会取整到1个page,具体可以看内核模块
HardwareCorrupted
当系统检测到内存的硬件故障时,会把有问题的页面删除掉,不再使用
PageTables
Page Table用于将内存的虚拟地址翻译成物理地址,随着内存地址分配得越来越多,Page Table会增大,/proc/meminfo中的PageTables统计了Page Table所占用的内存大小
区分以下概念:
- Page Cache:用于缓存磁盘上的文件数据,以加速文件读写操作
- Page Frame(页帧):物理内存的最小单位是page frame,每个物理页对应一个描述符(struct page),在内核的引导阶段就会分配好。只会随着物理内存的变大而引导时变大,不会动态增长。
KernelStack
每一个用户线程都会分配一个kernel stack(内核栈),内核栈虽然属于线程,但用户态的代码不能访问,只有通过系统调用(syscall)、自陷(trap)或异常(exception)进入内核态的时候才会用到
Bounce
老设备用,已经很少见了
用户进程使用
前置知识
Page Cache
Page Cache用于缓存磁盘上的文件数据,以加速文件读写操作
对于IO子系统来说,内核中的分层结构从上到下:

对Page Cache的分析基于linux v2.6.39
磁盘和内存时延对比
这主要是因为磁盘和内存的访问时延差太多了
根据https://colin-scott.github.io/personal_website/research/interactive_latency.html
由于每一年性能都不一样,选择到2020可见:
- L1缓存1ns
- 内存访问是100ns
- ssd随机读写是10us级别的
- 磁盘寻址是1ms级别的
顺便一提:
- 协程的上下文切换是10-100ns级别的,相当于最差进行了内存访问,可以有千万到上亿qps
- 而操作系统的上下文切换是10-100us级别的,最高只有几万到几十万的qps
数据结构
inode和address_space
在2.6版本以前,存在全局的page_hash_table数据里面,这是一个struct page的哈希表,《深入理解Linux虚拟内存管理》的10.2.1 页面高速缓存哈希表进行了详细介绍
在2.6以后变了,在《Linux内核设计与实现》的16.2.4 以前的页散列表中介绍了全局哈希表的缺点,最大的问题是一个全局锁导致性能瓶颈,所以改成了radix_tree基树(优化版本的字典树,在 linux 内核 5.0 版本中 radix_tree 已被替换成 xarray 结构)
优化后的数据结构叫做address_space,书中16.2.1 address_space对象说这个取名文不对题,应该叫做page cache entity或者physical_pages_of_a_file
它的字段在https://github.com/torvalds/linux/blob/v2.6.39/include/linux/fs.h#L630-L648:
1 | struct address_space { |
这里的host表示每个struct inode都会有一一对应的struct address_space,struct address_space相当于struct inode的扩展字段,也就是每个文件都有一个struct radix_tree_root的基树page_tree
1 | struct inode { |
address_space中引用的address_space_operations在https://github.com/torvalds/linux/blob/v2.6.39/include/linux/fs.h#L577-L613
1 | struct address_space_operations { |
radix树
具体来看下address_space中的struct radix_tree_root page_tree;
首先什么是radix树呢?他是Trie(字典)树的一种变种
Trie(字典)树是这样的:
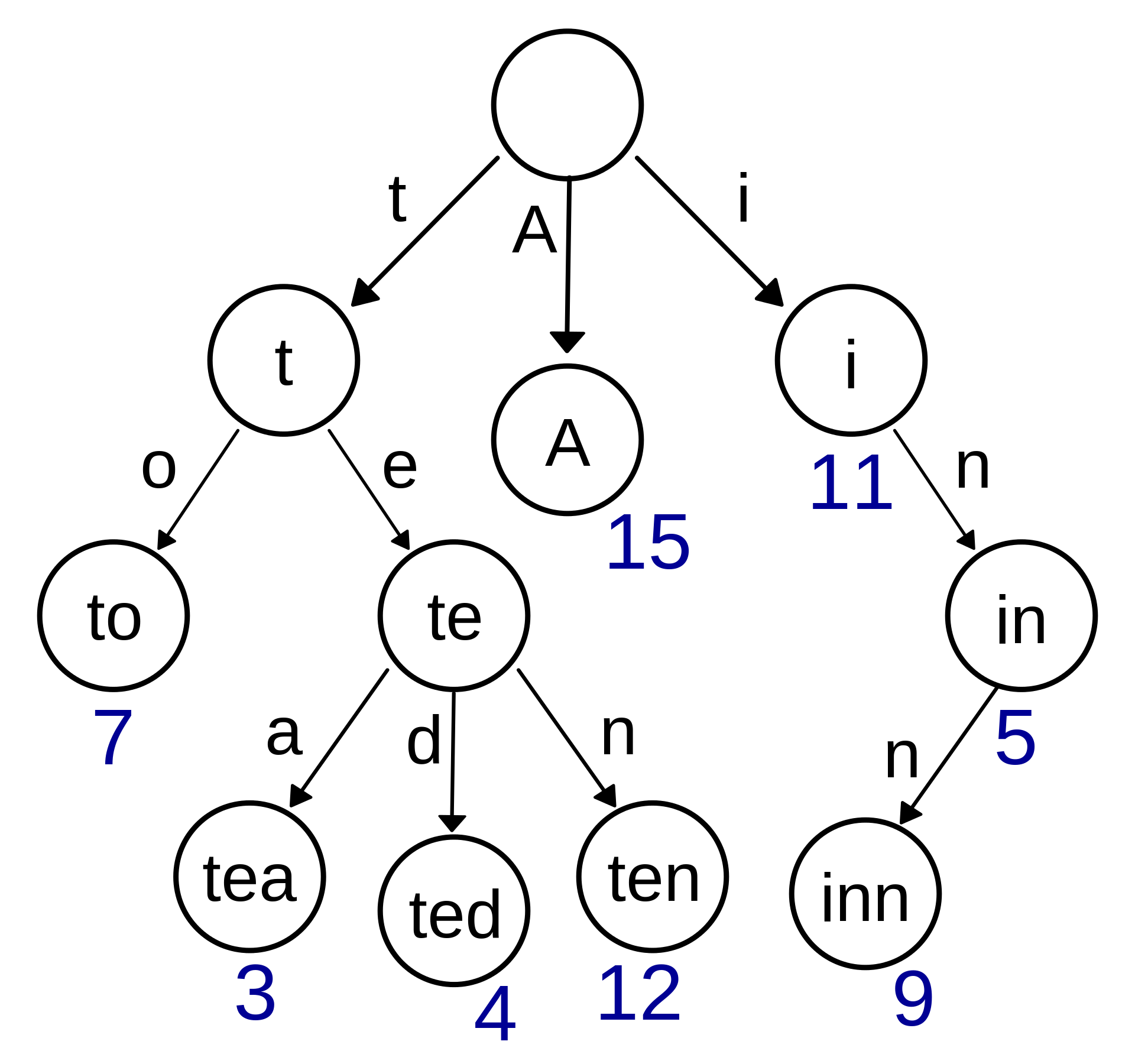
radix(基)树是这样的:
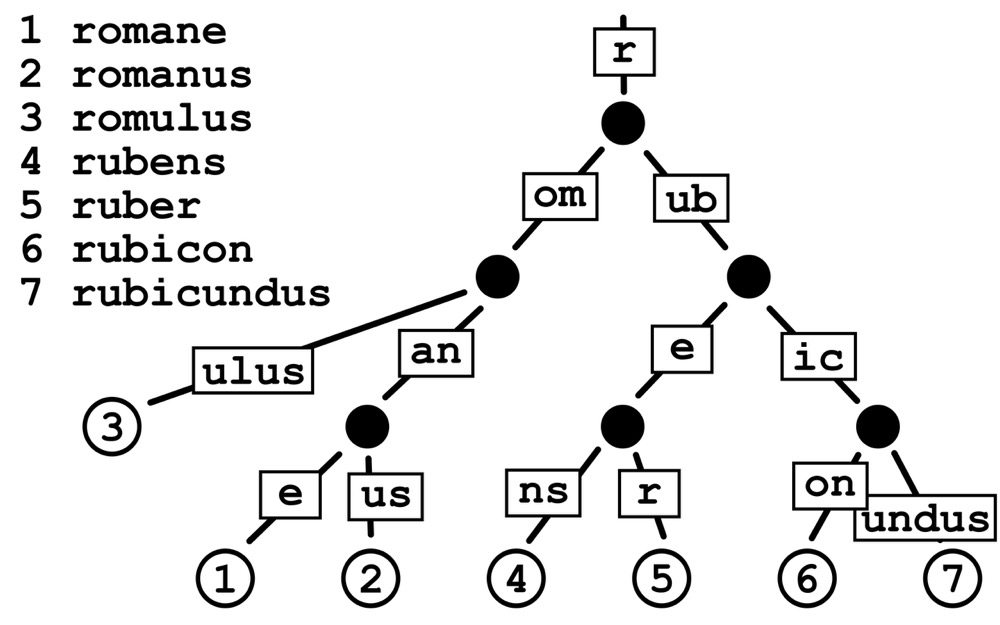
显然区别在于它不是按照每个字符长度做节点拆分,而是可以以1个或多个字符叠加作为一个分支。这就避免了长字符key会分出深度很深的节点。
struct address_space根据文件offset来查询页面的函数在这里:https://github.com/torvalds/linux/blob/v2.6.39/mm/filemap.c#L666-L700
1 | struct page *find_get_page(struct address_space *mapping, pgoff_t offset) { |
radix_tree_lookup_slot的相关算法都在https://github.com/torvalds/linux/blob/v2.6.39/lib/radix-tree.c#L371-L406,我注释好了代码
1 | void **radix_tree_lookup_slot(struct radix_tree_root *root, unsigned long index) |
所以这是一个按offset的二进制后缀,每次计算后RADIX_TREE_MAP_MASK位指向的slot的后缀radix树
1 |
一般来说RADIX_TREE_MAP_MASK为6,也就是每个radix树有64个子节点,那么radix树的效果如图

task_struct和inode的联系
那么进程是如何定位到打开了哪些文件呢
task_struct是表达进程的数据结构,定义在https://github.com/torvalds/linux/blob/v2.6.39/include/linux/sched.h#L1193-L1543
1 | struct task_struct { |
files_struct表达了进程打开了哪些文件,定义在https://github.com/torvalds/linux/blob/v2.6.39/include/linux/fdtable.h#L44-L59
1 |
|
这里就可以看到熟悉的struct file了,但是这里struct fdtable用来封装struct file**,并且定义了两个字段,然后还有一个单独的struct file*的fd_array,都有什么用呢?
在系统的第一个进程的定义中可以看到他们的联系(普通的进程fork也是这个联系,太复杂略过):https://github.com/torvalds/linux/blob/v2.6.39/fs/file.c#L416-L426
1 | struct files_struct init_files = { |
也就是说,初始化的时候实际上只有fd_array这一个实际的struct file*数组,它的大小是64
flowchart LR
A[struct fdtable __rcu *fdt] --> B[struct fdtable fdtab]
B --> C[struct file __rcu * fd_array]那么打开的文件大于64的时候怎么办呢?当然是临时扩展啦,新创建一个struct fdtable
flowchart LR
A[struct fdtable __rcu *fdt] --指向新的--> B[new struct fdtable]
C[struct fdtable fdtab] --这里还保留着--> D[struct file __rcu * fd_array]
D --拷贝过去--> B具体流程详见struct files_struct和struct fdtable和存储基础 — 文件描述符 fd 究竟是什么?
struct file直接指向struct inode,也指向了struct address_space:https://github.com/torvalds/linux/blob/v2.6.39/include/linux/fs.h#L933-L973
1 | struct file { |
在2.6.39中没有f_inode,这个版本是通过f_path定位到inode的,后续才修改了,例如一个struct file转换成struct inode的函数修改的commit如下:
1 | static inline struct inode *file_inode(struct file *f) |
每个进程会对同一个文件打开不同的struct file(不过fork的子进程会继承父进程的struct files_struct,也就是相同的struct file),但是一个文件只会有一个struct inode
因此task_struct和inode的关系如图:
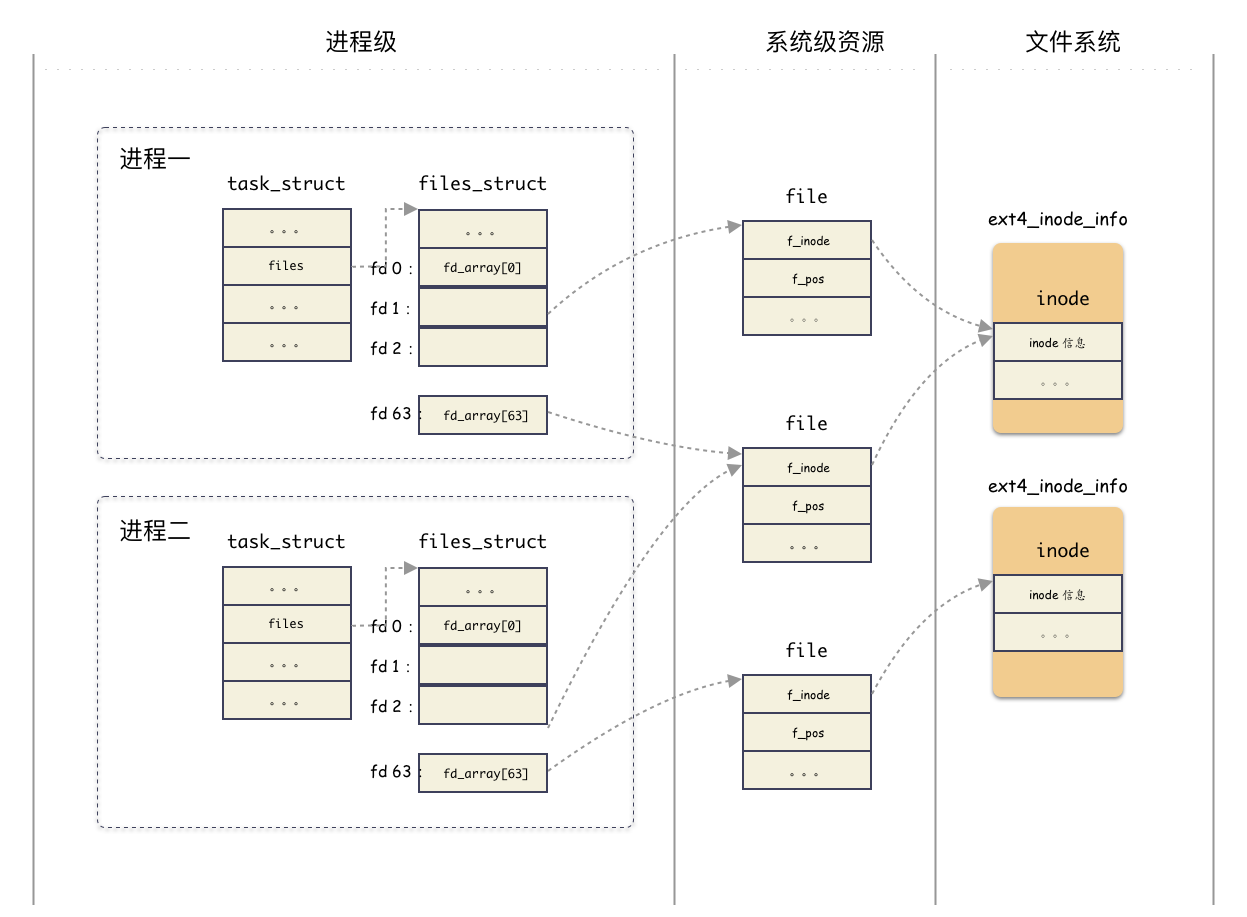
总结类图

BufferIO读写流程
在《Linux内核设计与实现》的16.2.2 address_space 操作中介绍了用户对文件进行读写的流程
简单来说
当用户对文件进行读写时,实际上是对文件的 页缓存 进行读写。所以对文件进行读写操作时,会分以下两种情况进行处理:
当从文件中读取数据时
如果要读取的数据所在的页缓存已经存在,那么就直接把页缓存的数据拷贝给用户即可。
否则,内核首先会申请一组空闲的内存页(页缓存),然后从文件中读取这一页并且预读一部分到页缓存,并且把页缓存的数据拷贝给用户。
当向文件中写入数据时
如果要写入的数据所在的页缓存已经存在,那么直接把新数据写入到页缓存即可。
否则,内核首先会申请一个空闲的内存页(页缓存),然后从文件中读取数据到页缓存,并且把新数据写入到页缓存中。
对于被修改的页缓存
- 如果太“脏”了,会触发同步回写
- 否则内核会定时把这些页缓存刷新到文件中。
下面具体分析流程,以ext3文件系统为例(2.6还没有ext4)
https://github.com/torvalds/linux/blob/v2.6.39/fs/ext3/file.c#L55-L71
1 | const struct file_operations ext3_file_operations = { |
syscall进入vfs虚拟文件系统后,在do_sync_read或者do_sync_write中调用的都是对应文件系统接口aio_read和aio_write
读
sequenceDiagram
participant syscall
participant read_write as fs/read_write.c
participant filemap as mm/filemap.c
participant readahead as mm/readahead.c
participant radix-tree as lib/radix-tree.c
syscall ->> read_write : read(unsigned int fd,<br> char* buf, size_t count)
read_write ->>+ read_write : 根据fd找file<br>根据file找当前进程偏移pos<br>vfs_read(file, buf, count, &pos)
read_write ->>+ read_write : do_sync_read(file, buf, count, &pos)
read_write ->>+ filemap : struct iovec iov = { .iov_base = buf, .iov_len = count }<br>struct kiocb kiocb{.ki_pos = pos}<br>unsigned long nr_segs = 1<br>file->f_op->aio_read(&kiocb, &iov, nr_segs, kiocb.ki_pos)<br>在ext3文件系统下,这里aio_read = do_generic_file_read
loop seg = 从1到nr_segs
filemap ->>+ filemap : read_descriptor_t desc{ .count = iov[seg].iov_len }<br>actor = file_read_actor<br>do_generic_file_read(file, &kiocb.ki_pos, &desc, actor)
filemap ->>+ filemap : 计算要读的第一页和最后一页<br>index = kiocb.ki_pos >> PAGE_CACHE_SHIFT<br>last_index = (kiocb.ki_pos + desc->count + PAGE_CACHE_SIZE-1) >> PAGE_CACHE_SHIFT<br>从page cache找要读的第一页<br>page = find_get_page(file->f_mapping, index)
filemap ->>+ radix-tree : radix_tree_lookup_slot(&file->f_mapping->page_tree, index)
radix-tree ->>- filemap : return page
alt 如果page不存在,同步预读
filemap ->>+ filemap : page_cache_sync_readahead(file->f_mapping, &file->f_ra, file, index, last_index - index);
filemap ->>- filemap : return
else 如果page存在,且PageReadahead(page) == true,那么异步预读
filemap ->>+ filemap : page_cache_async_readahead(file->f_mapping, &file->f_ra, file, index, last_index - index);
filemap ->>- filemap : return
end
filemap -> filemap : 将 page cache 中的数据拷贝到用户空间缓冲区 DirectByteBuffer 中<br>实际上是将物理页映射到了内核虚拟地址进行拷贝<br>actor(desc, page, offset, nr)<br>这里actor = file_read_actor
filemap ->>- filemap : return
end
filemap ->>- read_write : return
read_write ->>- read_write : return
read_write ->>- read_write : return其实最核心的逻辑就是filemap.c中do_generic_file_read,代码在这里https://github.com/torvalds/linux/blob/v2.6.39/mm/filemap.c#L1044-L1259
然后就是预读了
预读
最早的预读策略非常简单
- 当前窗口(current window): 表示进程本次文件请求可以直接读取的页面集合,这个集合中的页面全部已经缓存在 page cache 中,进程可以直接读取返回。当前窗口中包含进程本次请求的文件页以及上次内核预读的文件页集合。表示进程本次可以从 page cache 直接获取的页面范围。
- 预读窗口(ahead window):预读窗口的页面都是内核正在预读的文件页,它们此时并不在 page cache 中。这些页面并不是进程请求的文件页,但是内核根据空间局部性原理假定它们迟早会被进程请求。预读窗口内的页面紧跟着当前窗口后面,并且内核会动态调整预读窗口的大小(有点类似于 TCP 中的滑动窗口)。

当不停的顺序读取的时候,预读窗口会幂次增大,也就是如果只是顺序读了N页面,预读窗口已经是\(2+2^2+...+2^N\)
但是在2.6.22开始,遇到了重试读(retried read)和交织读的问题,所以在不改变大致逻辑的情况下修改了细节
以交织读为例,当在一个打开的文件中同时进行多个流(stream)的读取时,它们的读取请求会相互交织在一起,在内核看来好像是很多的随机读。更严重的是,目前的内核只能在一个打开的文件描述符中跟踪一个流的预读状态。因而即使内核对两个流进行预读,它们会相互覆盖和破坏对方的预读状态信息。
因此struct page引入了一个新的标记位:PG_readahead
在每次进行新预读时,算法都会选择本次预读的第一个新页面标记之。预读规则相应的改为:
- 当读到缺失页面(missing page),进行同步预读
- 当读到预读页面(PG_readahead page),进行异步预读
由于可以同时存在多个页面是PG_readahead状态,因此在多线程交织读的情况下,也可以保证异步预读逻辑的正确性
维护预读窗口的数据结构如下:
1 | struct file_ra_state { |
以一个预读示例来理解这些字段和流程
预读示例流程
来自linux预读机制(linux 4.14),我重点标黑了page_cache_sync_readahead和page_cache_async_readahead的触发条件
按4k顺序访问文件的[0, 8*4K]的数据(顺序访问),然后lseek到108*4k处访问文件(随机访问)。过程如下:
访问第0个page数据
page->index=0的页面在page cache中找不到,触发同步预读page_cache_sync_readahead,一次性读了4个page(read需要1个page,预读3个page。预读page数量与实际请求的page数量、file_ra_state->ra_pages有关,通过get_init_ra_size计算)。本次预读建立的预读窗口如下:
注意,预读窗口中第
ra->size - ra->async_size = 1个page,即page->index=1设置了PageReadahead标记。访问第1个page数据
page->index=1的页面在page cache中能找到(预读命中),不需要从存储器件中读取数据。又因该page有PageReadahead标记,触发异步预读page_cache_async_readahead,预读页面数量由get_next_ra_size计算得到,因为本次请求的数据起始位置与上一次读结束位置相同,属于顺序读,get_next_ra_size加大预读量,预读量从之前的4 page增大到8 page。本次预读建立的预读窗口如下:
注意,预读窗口中第
ra->size - ra->async_size = 0个page,即page->index=4设置了PageReadahead标记。访问第2、3个page数据
这两个page在page cache中可以找到(预读命中),直接从page cache中读取数据。
访问第4个page数据
page->index=4的页面在page cache中可以找到(预读命中),直接从page cache中读取数据。不过这个page设置了PageReadahead标记,触发异步预读page_cache_async_readahead,由于是顺序读,get_next_ra_size将预读量从8 page增大到16 page,本次预读建立的预读窗口如下:
后继的顺序访问流程重复上面过程,遇到page被标记成PageReadahead,增大预读量(最大不超过
struct file_ra_state->ra_pages)后启动异步预读。lseek跳到108*4k处访问第108个page数据
访问
page->index=108的page,不符合顺序读的条件,所以代码判断成随机读。如果是随机读,则不做预读,read请求几个页的数据,就从存储器件中读几个页数据(ondemand_readahead --> __do_page_cache_readahead)。注意,这次随机读,不会更改预读窗口状态。
代码分析
不管是同步预读page_cache_sync_readahead还是异步预读page_cache_async_readahead,实际上最终都是调用ondemand_readahead,只是其中的一个bool参数不同
1 | //参数解释 |
最关键的ondemand_readahead代码在https://github.com/torvalds/linux/blob/v2.6.39/mm/readahead.c#L396-L487,逻辑如下:
1 | static unsigned long |
接下来就该提交预读了
1 | unsigned long ra_submit(struct file_ra_state *ra, |
小结
其实预读算法在各个版本的代码实现上都有差异,老版本还有不少bug,因此没有必要太过抠细节
主要记住三点:
- 页面不存在会引起同步预读
- 页面存在的时候,为了解决交织读的问题,引入了PG_readahead(每次预读的第一个页面),一旦读到,那么触发异步预读
- 不管同步还是异步读,顺序读会翻倍扩大预读窗口
写
sequenceDiagram
participant syscall
participant read_write as fs/read_write.c
participant filemap as mm/filemap.c
participant inode as fs/ext3/inode.c
participant filemap1 as mm/filemap.c
syscall ->> read_write : write(unsigned int fd,<br> char* buf, size_t count)
read_write ->>+ read_write : 根据fd找file<br>根据file找当前进程偏移pos<br>vfs_write(file, buf, count, &pos)
read_write ->>+ read_write : do_sync_write(file, buf, count, &pos)
read_write ->>+ filemap : struct iovec iov = { .iov_base = buf, .iov_len = count }<br>struct kiocb kiocb{.ki_pos = pos}<br>unsigned long nr_segs = 1<br>file->f_op->aio_write(&kiocb, &iov, nr_segs, kiocb.ki_pos)<br>在ext3文件系统下,这里aio_write = generic_file_aio_write
filemap ->>+ filemap : __generic_file_aio_write(&kiocb, &iov, nr_segs, &iocb->ki_pos)
alt file->f_flags & O_DIRECT == false
filemap ->>+ filemap : 根据iov->iov_len累加得到count:<br>count = generic_segment_checks(&iov, &nr_segs)<br>written = 0<br>generic_file_buffered_write(&kiocb, &iov, nr_segs, iocb->ki_pos, &iocb->ki_pos, count, written)
filemap ->>+ filemap : struct iov_iter iov_iter{ .iov = iov, nr_segs = nr_segs, iov_offset = 0, count = count + written}<br>generic_perform_write(file, &iov_iter, iocb->ki_pos)
filemap ->>+ inode : struct page *page<br>bytes = 根据iov_iter转换<br>file->f_mapping->a_ops-><br>write_begin(iocb->ki_pos, bytes, &page)<br>这里write_begin = ext3_write_begin
inode ->>+ filemap1 : index = iocb->ki_pos >><br> PAGE_CACHE_SHIFT<br>page = grab_cache_page_write_begin<br>(file->f_mapping, index)
filemap1 ->> filemap1 : 去page cache查找要写入的页面<br>struct page *page = find_lock_page(file->f_mapping, index)
alt page 不存在
filemap1 ->> filemap1 : 创建新页面page = __page_cache_alloc()<br>加入lru链表 add_to_page_cache_lru()
end
filemap1 ->>- inode : return page
inode ->> inode : ext3日志准备工作:ext3_journal_start()
inode ->>- filemap : return
filemap ->> filemap : offset = (iocb->ki_pos & (PAGE_CACHE_SIZE - 1))<br>将page这物理页映射到了内核虚拟地址<br>将用户缓存区buff中的待写入数据拷贝到page中<br>iov_iter_copy_from_user_atomic(page, iov_iter, offset, bytes)
filemap ->>+ inode : file->f_mapping->a_ops->write_end()<br>在ext3文件系统的默认Order模式<br>write_end = ext3_ordered_write_end(page, ...)
inode ->> inode : 将写入的缓存页标记为脏页:block_write_end(page, ...)<br>ext3日志写入:ext3_journal_stop()
inode ->>- filemap : return
filemap ->> filemap : 脏页回写入口:balance_dirty_pages_ratelimited
filemap ->>- filemap : return
filemap ->>- filemap : return
end
filemap ->>- filemap : return
filemap ->>- read_write : return
read_write ->>- read_write : return
read_write ->>- read_write : return脏页回写
经过前边对文件写入过程的介绍我们看到,用户进程在对文件进行写操作的时候只是将待写入数据从用户空间的缓冲区 buff 写入到内核中的 page cache 中就结束了。后面内核会对脏页进行延时写入到磁盘中。
上面只列出了脏页回写的入口balance_dirty_pages_ratelimited,下面依次列出流程中四个函数的逻辑并注释
1 | // 满足速率限制的脏页面平衡函数,以1个页面为单位 |
可以看到,在写入的时候,如果太脏了,会唤醒flusher线程执行后台写回操作,初次之外,系统会定时的启动fluster线程进行写回
具体分析看这这一篇就行内核回写脏页的触发时机
缺页中断
理解了缺页中断,就对下图的虚拟地址有了一个整体的把握
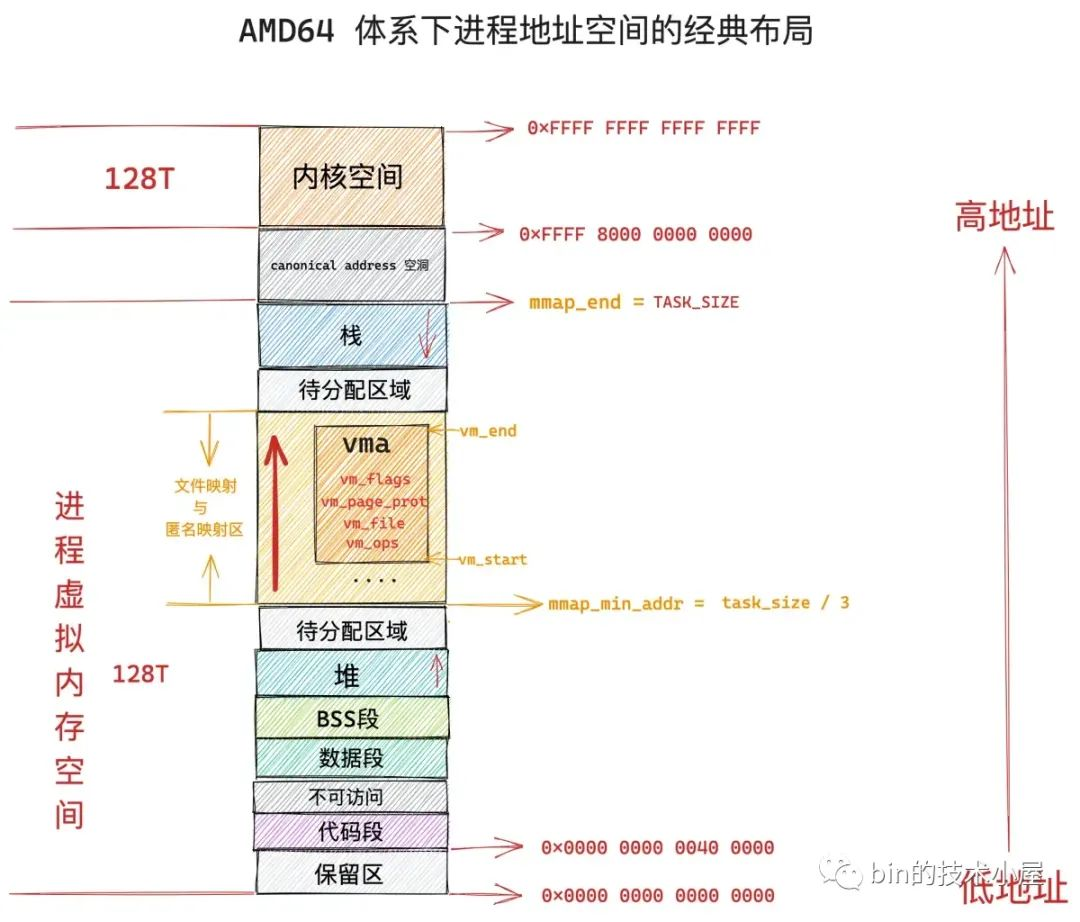
缺页中断不再基于linux 2.6.39进行源码分析,这是因为非线性映射已经被干掉了:https://github.com/torvalds/linux/commit/9b4bdd2ffab9557ac43af7dff02e7dab1c8c58bd
它的流程太过老旧,所以基于5.4版本进行分析
缺页中断在日常中最常见的应用,就是malloc在分配大块内存 (128KB) 使用 mmap 分配内存空间,但是这里只是在进程的虚拟地址空间中寻找出一段空闲的虚拟内存区域 vma 然后分配给本次映射而已。
1 | unsigned long mmap_region(struct file *file, unsigned long addr, |
在对这一块内存区域读或者写的时候,发生缺页中断,才会真正的分配内存空间
SysV shmat和mmap
首先介绍一下Linux的映射:它分成两种接口,基本存在两个使用步骤:创建,映射
SysV的共享内存映射
创建(shmget),映射(shmat)
这个祖传的共享内存已经很少见了,在UNIX环境高级编程(第三版)中15.6中有简单介绍,并且进行了负面评价:
除非被一个进程明确的删除,否则它始终存在于内存里,直到系统关机,因此很容易造成泄露
mmap
映射可以分类:
使用MAP_SHARED的flag
直接把文件映射到当前的进程空间,所有的修改会直接反应到文件的Page Cache,然后由内核自动同步到映射文件上。
使用MAP_PRIVATE的flag
使用COW的方式,把文件映射到当前的进程空间,修改操作不会改动源文件
这个隔离对于fork的父子进程也是存在的
按是否匿名(MAP_ANONYMOUS的flag)分类,由于匿名特性不在POSIX中,因此可以分类:
非POSIX:
使用MAP_ANONYMOUS的flag
由于是匿名的,因此直接就包含了创建和映射
mmap(…MAP_ANONYMOUS|MAP_SHARED…),这一般用于父子进程通信mmap(…MAP_ANONYMOUS|MAP_PRIVATE…)则常见于malloc分配大块内存 (128KB)POSIX:
不使用使用MAP_ANONYMOUS的flag
创建(shm_open,open),映射(mmap)
以MAP_SHARED举例的使用方式:
1
2
3
4
5
6
7
8
9
10//使用 shm_open 创建或打开一个共享内存对象。
int fd = shm_open("/my_shm", O_CREAT | O_RDWR, 0666);
//使用 ftruncate 设置共享内存对象的大小。
ftruncate(fd, size);
//使用 mmap 将共享内存对象映射到进程的地址空间。
void* ptr = mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
//使用 munmap 解除映射。
munmap(ptr, size);
//使用 shm_unlink 删除共享内存对象。
shm_unlink("/my_shm");
数据结构和初始化
页(struct page)
页面的表达单位
页帧,页框(page frame)
和物理内存一对一,存在全局的mem_map数据里面,这是一个struct page的数组
https://github.com/torvalds/linux/blob/master/mm/memory.c#L101
页表(Page Table)
每个进程都有自己的页表,由每个进程管理地址空降的struct mm_struct的pgd类型指针为入口,可以获取到整个四级页表

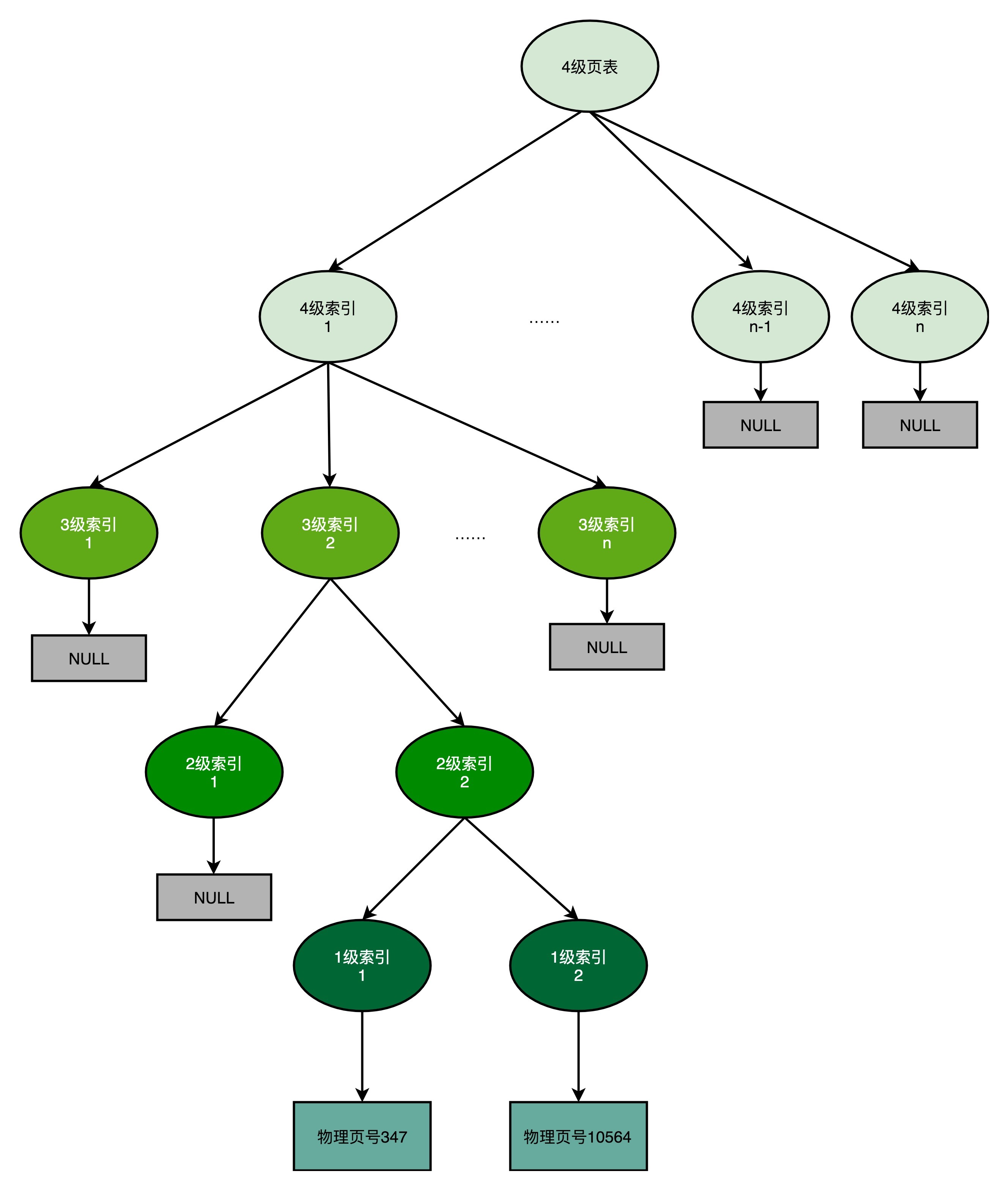
核心思想就在于 按需分配,可以想象成一个字典树
初始化
页表到底是保存在内核空间中还是用户空间中? - bin的技术小屋的回答 - 知乎
而进程的顶级页表起始地址 pgd 又是在什么时候被内核设置进去的呢?
很显然这个设置的时机是在进程被创建出来的时候,当我们使用 fork 系统调用创建进程的时候,内核在 _do_fork 函数中会通过 copy_process 将父进程的所有资源拷贝到子进程中,这其中也包括父进程的虚拟内存空间。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr,
unsigned long tls)
{
......... 省略 ..........
struct pid *pid;
struct task_struct *p;
......... 省略 ..........
// 拷贝父进程的所有资源
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace, tls, NUMA_NO_NODE);
......... 省略 ..........
}
页表项(PTE)
树的节点是页表项(全称是Page Table Entry,简写PTE)
在《深入理解Linux虚拟内存管理》的3.2描述页表项进行了一定的介绍,PTE包含了以下信息:
物理页框号 (Page Frame Number, PFN)
指向实际的物理内存地址
pte到pfn的转换在https://github.com/torvalds/linux/blob/v2.6.39/arch/x86/include/asm/pgtable.h#L140
1
2
3
4static inline unsigned long pmd_pfn(pmd_t pmd)
{
return (pmd_val(pmd) & PTE_PFN_MASK) >> PAGE_SHIFT;
}通过掩码,然后右移一定的保护和状态位
保护和状态位:权限和状态标志
常见的标志包括:是否有效(Present bit)、读写权限(Read/Write bit)、用户或内核模式(User/Supervisor bit)、是否已访问(Accessed bit)、是否已修改(Dirty bit)等
具体在这里https://github.com/torvalds/linux/blob/v2.6.39/arch/x86/include/asm/pgtable_types.h#L34-L49
vm_area
每个进程的mm_struct到address_space的关系如下
其中vm_area_struct 结构体 中的 vm_file 成员 是 " 内存映射 “ 中的 ” 文件映射 " 类型中 被映射的 文件 , 如果是 " 匿名映射 " 类型的 " 内存映射 " , 该成员为 NULL
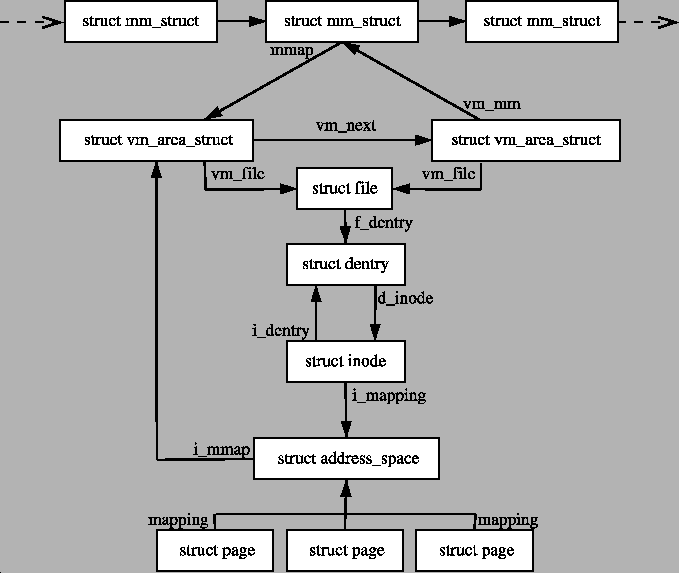
获取进程地址空间:
mm_struct包含进程的所有内存区域,通过mmap字段(一个vm_area_struct链表)描述。这些描述了进程的虚拟内存布局。虚拟内存区域 (VMA):
每个
vm_area_struct(VMA)对应一个连续的虚拟地址区域。如果这个 VMA 是文件映射区域(即不是匿名映射),则其vm_file字段指向相关的文件。文件结构:
vm_file是一个指向file结构的指针,代表与这个内存区域相关的文件。获取 inode:
file结构的f_inode字段指向文件的inode结构。获取 address_space:
inode结构包含一个i_mapping字段,该字段指向与文件相关联的address_space结构。
vma初始化
vm_area_struct是在mmap的时候进行初始化的,根据以下代码,可以发现分为两类:
非文件映射:mmap(…MAP_ANONYMOUS|MAP_PRIVATE…)
它的vma->vm_ops为空,vma->file也为空
文件映射:除去上面的全部(非匿名映射和共享匿名映射,共享匿名映射实际上还是指向了一个tmpfs的匿名文件)
它的vma->vm_ops不为空,vma->file也不为空
1 | unsigned long mmap_region(struct file *file, unsigned long addr, |
流程
CPU的MMU器件和操作系统约定好了页表的遍历方式,在访问一个虚拟地址的时候,页表发现它的页表项是空的
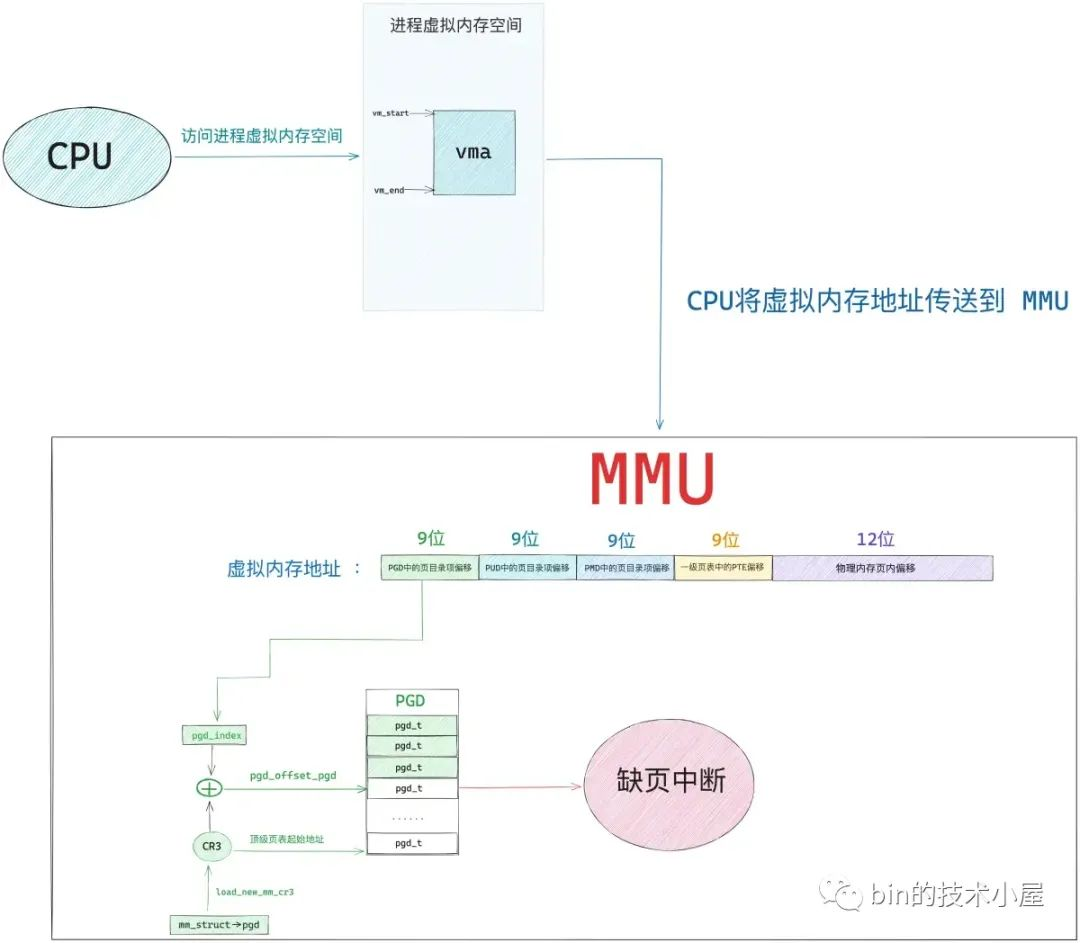
所以 MMU 会产生一个缺页中断,进程从用户态转入内核态来处理这个缺页异常。
此时 CPU 会将发生缺页异常时,进程正在使用的相关寄存器中的值压入内核栈中。比如,引起进程缺页异常的虚拟内存地址address会被存放在 CR2 寄存器中。同时 CPU 还会将缺页异常的错误码 error_code 压入内核栈中。
随后内核会在 do_page_fault 函数中来处理缺页异常,该函数的参数都是内核在处理缺页异常的时候需要用到的基本信息:
1 | dotraplinkage void |
struct pt_regs 结构中存放的是缺页异常发生时,正在使用中的寄存器值的集合。
sequenceDiagram
participant fault as arch/x86/mm/fault.c
participant memory as mm/memory.c
participant memory1 as mm/memory.c
participant memory2 as mm/memory.c
fault ->>+ fault : do_page_fault(regs, error_code, address)<br>转发给了__do_page_fault(regs, error_code, address)
alt address >= TASK_SIZE_MAX
fault ->> fault : 内核缺页中断,主要处理vmalloc的,不是本文重点<br>do_kern_addr_fault(regs, error_code, address)
else
fault ->>+ fault : do_user_addr_fault(regs, error_code, address)
fault ->>+ fault : 获取当前的进程结构<br>struct task_struct *tsk = get_current()<br>获取当前的进程虚拟内存结构<br>struct mm_struct *mm = tsk->mm<br>根据地址address从进程的vm_area红黑树中找到对应的vma<br>vma = find_vma(mm, address)
alt vma不存在
fault ->> fault : 直接返回
else vma存在且<br>vma->vm_start > address<br>且 vma->vm_flags & VM_GROWSDOWN,说明是栈区
fault ->> fault : 扩容一下栈区,然后直接返回
else vma存在且<br>vma->vm_start <= address
fault ->>+ memory : uint flag是根据error_code转换而来的<br>uint fault = handle_mm_fault(vma, address, flag)<br>转发给__handle_mm_fault(vma, address, flag)
memory ->>+ memory : pgd_t *pgd = pgd_offset(mm, address)<br>然后从pgd开始遍历页表,创建页表项<br>struct vm_fault vmf = {.vma = vma, .address = address & PAGE_MASK}<br>handle_pte_fault(&vmf)
alt 目录项为空:<br>pmd_none(*vmf->pmd) == true
memory ->> memory : vmf->pte = NULL
else 目录项不为空
memory ->> memory : vmf->pte = pte_offset_map(vmf->pmd, vmf->address)
else 目录项不为空,<br>但是计算出的pmd_none(vmf->pte) == true
memory ->> memory : vmf->pte = NULL
end
alt vmf->pte == NULL且vmf->vma->vm_ops 为空
memory ->>+ memory1 : 处理匿名页逻辑:do_anonymous_page(vmf)
memory1 ->> memory1 : 从伙伴系统中分配物理页面,如果失败就直接oom<br>page = alloc_zeroed_user_highpage_movable(vma, vmf->address)<br>创建页表项entry = mk_pte(page, vma->vm_page_prot)
alt vma->vm_flags & VM_WRITE == true
memory1 ->> memory1 : 设置页面脏且可写:entry = pte_mkwrite(pte_mkdirty(entry));
end
memory1 ->> memory1 : 将匿名页添加到 LRU 链表中:lru_cache_add_active_or_unevictable(page, vma)<br>将entry赋值给pte:set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry)<br>刷下mmu:update_mmu_cache(vma, vmf->address, vmf->pte)
memory1 ->>- memory : return
else vmf->pte == NULL且vmf->vma->vm_ops 不为空
memory ->>+ memory1 : 处理文件页逻辑:do_fault(vmf)
alt 读操作引起缺页:vmf->flags & FAULT_FLAG_WRITE == false
memory1 ->>+ memory2 : do_read_fault(vmf)
memory2 ->>+ memory2 : 预读一部分do_fault_around(vmf),详见Page Cache部分分析<br>finish_fault(vmf)
memory2 ->> memory2 : 将创建出来的物理内存页映射到 address 对应在页表中的 pte 中<br>alloc_set_pte(vmf, vmf->memcg, page)
memory2 ->>- memory2 : return
memory2 ->>- memory1 : return
else 私有写操作引起缺页,vmf->flags & FAULT_FLAG_WRITE == false && vma->vm_flags & VM_SHARED == false
memory1 ->>+ memory2 : do_cow_fault(vmf)
memory2 ->>+ memory2 : 从伙伴系统重新申请一个用于写时复制的物理内存页:<br>page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, vmf->address)<br>finish_fault(vmf)
memory2 ->>+ memory2 : 将创建出来的物理内存页映射到 address 对应在页表中的 pte 中<br>alloc_set_pte(vmf, vmf->memcg, page)
alt vma->vm_flags & VM_WRITE == true
memory2 ->> memory2 : 设置页面脏且可写:entry = pte_mkwrite(pte_mkdirty(entry));
end
memory2 ->>- memory2 : return
memory2 ->>- memory2 : return
memory2 ->>- memory1 : return
else 共享写操作引起缺页,vmf->flags & FAULT_FLAG_WRITE == false && vma->vm_flags & VM_SHARED == true
memory1 ->>+ memory2 : do_shared_fault(vmf)
memory2 ->>+ memory2 : 从 page cache 中读取文件页:__do_fault(vmf)<br>finish_fault(vmf)
memory2 ->>+ memory2 : 将创建出来的物理内存页映射到 address 对应在页表中的 pte 中<br>alloc_set_pte(vmf, vmf->memcg, page)
alt vma->vm_flags & VM_WRITE == true
memory2 ->> memory2 : 设置页面脏且可写:entry = pte_mkwrite(pte_mkdirty(entry));
end
memory2 ->>- memory2 : return
memory2 ->> memory2 : 判断是否将脏页回写:fault_dirty_shared_page(vma, vmf->page);
memory2 ->>- memory2 : return
memory2 ->>- memory1 : return
end
memory1 ->>- memory : return
else vmf->pte存在<br>但是vmf->pte的flag标识当前页面swapout到磁盘中
memory ->>+ memory1 : 从磁盘搞回来:do_swap_page(vmf)
memory1 ->>- memory : return
else vmf->pte存在<br>但是vmf->pte的flag标识当前页面被NUMA balance了
memory ->>+ memory1 : 从其他cpu搞回来:do_numa_page(vmf)
memory1 ->>- memory : return
else vmf->pte存在,也没有奇怪的flag<br>但是没有写权限,当前的vma有写权限,可能要写时复制
memory ->>+ memory1 : 例如页面mmap以后,发生了读操作,会将pte设为只读<br>又或者私有页面发生了fork,在copy_one_pte中<br>会将父子进程都设为pte只读<br>do_wp_page(vmf)
alt 是匿名页且引用计数为1: PageAnon(vmf->page) == true && reuse_swap_page(vmf->page, &total_map_swapcount)
memory2 ->> memory2 : 不做写时复制处理,将 pte 改为可写:wp_page_reuse(vmf)
else 不是匿名页且共享映射 : PageAnon(vmf->page) == false && vma->vm_flags & (VM_WRITE|VM_SHARED) == true
memory2 ->> memory2 : 不做写时复制处理,将 pte 改为可写,并看看共享页面是否要回写:wp_page_shared(vmf)
else 不是匿名页且私有映射: PageAnon(vmf->page) == false && vma->vm_flags & (VM_WRITE|VM_SHARED) == false
memory2 ->>+ memory2 : wp_page_copy(vmf)
memory2 ->> memory2 : 从伙伴系统中分配物理页面,如果失败就直接oom<br>page = alloc_page_vma(vma, vmf->address)<br>将原来内存页 old page 中的内容拷贝到新内存页 new page 中:cow_user_page(new_page, old_page, vmf->address, vma)<br>创建页表项entry = mk_pte(new_page, vma->vm_page_prot)<br>将匿名页添加到 LRU 链表中:lru_cache_add_active_or_unevictable(new_page, vma)<br>将entry赋值给pte:set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry)<br>刷下mmu:update_mmu_cache(vma, vmf->address, vmf->pte);
memory2 ->>- memory2 : return
else 是匿名页且引用计数不为1 : PageAnon(vmf->page) == true && reuse_swap_page(vmf->page, &total_map_swapcount) == false
memory2 ->> memory2 : 同上:wp_page_copy(vmf)
end
memory1 ->>- memory : return
end
memory ->>- memory : return
memory ->>- fault : return fault
alt fault & VM_FAULT_MAJOR == ture
fault ->> fault : 更新主缺页异常统计信息:tsk->maj_flt++
else
fault ->> fault : 更新次缺页异常统计信息:tsk->min_flt++
end
end
fault ->>- fault : return
fault ->>- fault : return
end
fault ->>- fault : return写时拷贝
这里非常让人迷惑的一点,是同时存在do_cow_fault写时拷贝,和do_wp_page下的wp_page_copy写时拷贝
其中do_cow_fault是mmap(…MAP_PRIVATE…) 刚映射完,pte此时不存在,就发生了写入,又不能写这个文件,那必须要写时拷贝了
而wp_page_copy是pte已经存在了,但是只读,而对应的vma又是可写的,常见于两种情况:
读操作(不管什么mmap映射),都只会给pte设置只读属性,如果这是一个私有页面,那么写入就需要进行写时拷贝了
大名鼎鼎的fork写时拷贝:
在fork时,对于私有的匿名页或者文件页,都会将其pte设置为只读的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26static inline unsigned long
copy_one_pte(struct mm_struct *dst_mm, struct mm_struct *src_mm,
pte_t *dst_pte, pte_t *src_pte, struct vm_area_struct *vma,
unsigned long addr, int *rss)
{
/*
* If it's a COW mapping, write protect it both
* in the parent and the child
*/
if (is_cow_mapping(vm_flags) && pte_write(pte)) {
// 设置父进程的 pte 为只读
ptep_set_wrprotect(src_mm, addr, src_pte);
// 设置子进程的 pte 为只读
pte = pte_wrprotect(pte);
}
// 获取 pte 中映射的物理内存页(此时父子进程共享该页)
page = vm_normal_page(vma, addr, pte);
// 物理内存页的引用技术 + 1
get_page(page);
}
static inline bool is_cow_mapping(vm_flags_t flags)
{
// vma 是私有可写的
return (flags & (VM_SHARED | VM_MAYWRITE)) == VM_MAYWRITE;
}然后假设子进程先进行写入,由于pte只读,会触发
do_wp_page的缺页中断对于匿名页会查看引用计数,不为1就触发
wp_page_copy的写时拷贝对于文件页直接触发
wp_page_copy的写时拷贝父进程再进行写入的时候
此时该页面的引用计数归1,匿名页就不会触发写时拷贝了
文件页依然还是需要触发
wp_page_copy的写时拷贝
小结一下:
- 私有文件页不管如何,写入都是需要写时拷贝的,只是有时候因为先读取,所以根据pte是否空,逻辑路径上存在
do_cow_fault和wp_page_copy - 私有匿名页根据引用计数来判断,只要只有一个进程在用,写入时就不用触发写时拷贝
小结
CPU的MMU器件和操作系统约定好了页表的遍历方式,在访问一个虚拟地址的时候,页表发现它的页表项是空的,随后就会在CR2寄存器触发缺页异常让内核来处理
内核根据触发缺页异常的虚拟地址查vma,校验过vma后,根据vma的flag做以下操作(以mmap举例vma的flag)
当pte为空时
mmap(…MAP_ANONYMOUS|MAP_PRIVATE…)的vma下
进入
do_anonymous_page中最常见的malloc在内存不足导致的的oom就是这里的逻辑
分配了一个物理页面放入pte,如果是读取,那么pte是只读的
mmap(…MAP_SHARED…) 和 mmap(…MAP_ANONYMOUS|MAP_SHARED…)和mmap(…MAP_PRIVATE…) 的vma下
进入
do_fault中,也就是其他的任何mmap都会进这里(这里可以认为是“文件”处理,因为共享匿名映射实际上指向了tmpfs的一个文件,见vma初始化)如果是读操作进入
do_read_fault分配了一个物理页面放入pte,并且拷贝文件数据,和BufferIO读取逻辑差不多,也有预读逻辑,但是预读的只会放在Page Cache
此时pte是只读的
如果是写操作
mmap(…MAP_SHARED…) 和 mmap(…MAP_ANONYMOUS|MAP_SHARED…)的vma下
进入
do_shared_fault分配了一个物理页面放入pte,并且拷贝文件数据,和BufferIO写入逻辑差不多,也有脏页逻辑
mmap(…MAP_PRIVATE…) 的vma下
进入
do_cow_fault分配了一个物理页面放入pte,并且拷贝文件数据,触发写时拷贝,只是写内存,没有脏页回写逻辑
当pte不为空时
如果pte是只读的,对应vma区域可写,进入
do_wp_pagemmap(…MAP_ANONYMOUS|MAP_PRIVATE…)且引用计数不为1,或者mmap(…MAP_PRIVATE…)
那么一样会发生写时拷贝
文件页逻辑和
do_cow_fault基本一致否则赋予写权限,只是文件页要看下脏页回写逻辑
还有swapout和numa_balance的逻辑,生产环境都是关闭的,因此可以忽略
总的来说
- 私有文件页mmap(…MAP_PRIVATE…)不管如何,写入都是需要写时拷贝的
- 私有匿名页mmap(…MAP_ANONYMOUS|MAP_PRIVATE…)根据引用计数来判断是否需要写时拷贝
- 共享文件页mmap(…MAP_SHARED…)和共享匿名页mmap(…MAP_ANONYMOUS|MAP_SHARED…)都相当于BufferIO读写文件
用户进程内存的LRU分类
Page Cache和用户进程的内存都在LRU上
Kernel的页面回收算法(Page Frame Reclaiming)使用的数据结构,只是表现上像LRU,总结《深入理解Linux虚拟内存管理》的10.1章节页面替换策略内容:
新页面会被加入inactive_list,然后通过mark_page_accessed移动到active_list
定时或inactive_list不足的时候,会使用refill_inactive尝试扩大inactive_list:对于active_list的尾部元素,如果被引用过,就放回到头部,然后检查下一个页面;如果没被引用过,放进inactive_list
当某个匿名内存页被进程访问时,根据内存页所在的 LRU 链表作不同的操作:
- 如果内存页原来处于
活跃链表中,那么就会把此内存页的PG_referenced设置为 1。- 如果内存页原来处于
非活跃链表中,并且PG_referenced为 0。那么将内存页的PG_referenced标志位设置为 1。- 如果内存页原来处于
非活跃链表中,并且PG_referenced为 1。那么将会把内存页从非活跃链表移动到活跃链表,并且将PG_referenced设置为 0。内存淘汰时,只能从
非活跃链表中进行淘汰,淘汰过程如下:
- 从
非活跃链表的尾部开始进行内存淘汰,如果内存页的PG_referenced标志位为 1 时,将跳过此内存页,并且将此内存页的PG_referenced标志位设置为 0。- 如果内存页的
PG_referenced标志位为 0 时,那么将此内存页写入到交换分区中,并且将所有与此内存页的映射解除绑定,然后释放此内存页。上述过程是由
shrink_inactive_list函数完成另外,处于
活跃链表的内存页也有衰退的过程,衰退过程如下:
- 如果内存页的
PG_referenced标志位为 1,那么衰退过程将会把此内存页的PG_referenced标志位设置为 0。- 如果内存页的
PG_referenced标志位为 0,那么衰退过程将会把此内存页移动到非活跃链表中。上述过程是由
shrink_active_list函数完成,如下图所示:
2.6.18.1版本下:
函数 shrink_zone()
- 其中,shrink_zone() 函数是 Linux 操作系统实现页面回收的最核心的函数之一,它实现了对一个内存区域的页面进行回收的功能,该函数主要做了两件事情:
- 将某些页面从 active 链表移到 inactive 链表,这是由函数 shrink_active_list() 实现的。
- 从 inactive 链表中选定一定数目的页面,将其放到一个临时链表中,这由函数 shrink_inactive_list() 完成。该函数最终会调用 shrink_page_list() 去回收这些页面。
- 函数 shrink_page_list() 返回的是回收成功的页面数目。
以是否可回收有三种分类:
Inactive:长时间未被访问过的内存页,可以回收
Active:最近被访问过的内存页,不可以回收
Unevictable:永远不可以回收
包括VM_LOCKED的内存页、SHM_LOCK的共享内存页(又被统计在”Mlocked”中),和ramfs
以回收方式有两种分类
文件页(File-backed pages)
又叫文件映射页,这些内存页映射到磁盘上的文件。
当程序读取文件或内存映射文件时(例如进程的代码,依赖的动态库等),数据被加载到这些页中。它们可以通过 Page Cache 进行缓存。
在内存不足的时候可以直接写回对应的硬盘文件里,称为page-out
匿名页(Anonymous pages)
这些页不是直接从文件中读取的(例如进程的堆、栈)
在内存不足时就只能写到硬盘上的交换区(swap)里,称为swap-out
顺便对比一下ramfs和tmpfs
特性 tmpfs ramfs 是否固定大小 是 否 是否使用swap 是 否 重启后数据会丢失 是 是 tmpfs是内存文件系统,所以不能page-out,只能swap-out,属于匿名页
ramfs也是内存文件系统,但不能swap-out,所以不可回收,属于Unevictable
按是否文件系统分类
Cached
这就是指Page Cache的内存页,在缺页中断中提到,由于mmap(…MAP_ANONYMOUS|MAP_SHARED…)实际上是基于tmpfs的,也会存在在Page Cache上
所以虽然不能pageout,但是也算在Cached里面
Mapped
Page Cache中和进程相关的页面,就是Mapped
当一个文件不再与进程关联之后,原来在Page Cache中的页面并不会立即回收,仍然被计入Cached,这个UnMapped就是(Cached - Mapped)
Shmem
专门指tmpfs的内存
而mmap(…MAP_ANONYMOUS|MAP_SHARED…)实际上是基于tmpfs,那么这一部分就会记入Shmem
如果这一部分内存正在被进程使用,那么就会进入Mapped
Buffers
块设备(block device)所占用的缓存页
AnonPages
mmap(…MAP_ANONYMOUS|MAP_PRIVATE…)的页面,和进程相关联,进程退出就退出
这里不会计算mmap(…MAP_ANONYMOUS|MAP_SHARED…)的页面,因为是按文件系统分类的,这部分页面是tmpfs算在Shmem了
AnonHugePages
这是Transparent HugePages ,又叫做透明大页
由于Linux Kernel 2.6引入的Huge Pages,又叫做标准大页,必须使用文件系统来使用,很难使用,因此引入了透明大页
来让应用的开发者更容易使用,根据资料Linux 标准大页和透明大页
Oracle 官方虽然推荐我们使用 Huge pages ,但是却建议我们关闭 Transparent Huge pages ,因为透明大页存在一些问题:
- 在 RAC 环境下 透明大页( TransparentHugePages )会导致异常节点重启,和性能问题;
- 在单机环境中,透明大页( TransparentHugePages ) 也会导致一些异常的性能问题;
按LRU的pageout, swapout分类
Inactive(anon) 或 Active(anon)
不能pageout,但是可以swapout的在这里
Inactive(file) 或 Active(file)
能pageout的在这里,虽然tmpfs是个文件系统,但是后面实际上是内存页,只能swapout,所以在这个链表里面
SwapCached
首先要区分:
- Swap Cache:
- 是内核中用于临时存储即将写入或已经从交换空间(swap space)读入的页的缓存。
- 它的作用是优化性能,减少对磁盘的重复 I/O 操作。当页被写入 swap 空间之前或从 swap 空间读入后会短暂地存在于 swap cache 中。
Swap Space:
是指硬盘上分区或文件用作虚拟内存的持久性存储区域。
当物理内存不足时,系统会将不常用的页移到 swap space 中,这样可以腾出内存用于当前需要的程序。
因此能被swap out的,都有可能短暂的进入SwapCached,然后在swap out完成以后从SwapCached删除
Unevictable
不能pageout也不能swapout的在这里
Hugepages
AnonHugePages提过的,标准大页,我很久以前挖矿用过这个,确实很难用,一般很少见到有用的,遇到了再更新
meminfo实战
统计cgroup内存不准确
cgroup内存数据简介
Cgroup按层级管理,每个节点都包含一组文件,用于统计由这个节点包含的控制组的某些方面的指标。如下:

查看根控制组,如下:
1 | ~ ls /sys/fs/cgroup/memory/ |
具体分析如下:
1 | cgroup.event_control #用于eventfd的接口 |
cgroup.event_control比较复杂:详见https://docs.redhat.com/zh-cn/documentation/red_hat_enterprise_linux/7/html/resource_management_guide/sec-memory#sec-memory
其中需要关注以下3个指标:
- memory.limit_in_bytes:限制当前控制组可以使用的内存大小。对应K8s、Docker下memory limit指标。
- memory.usage_in_bytes:当前控制组里所有进程实际使用的内存总和,约等于memory.stat文件下的RSS+Cache指标值。
- memory.stat:当前控制组的内存统计详情。
在memory.stat下,就可以看到和meminfo相似的数据了,展示一下数据并且注释
1 | ~ cat /sys/fs/cgroup/memory/memory.limit_in_bytes |
Docker和K8S的算法是不一样的
| 命令 | 生态 | Memory Usage计算方式 |
|---|---|---|
docker stat |
Docker | memory.usage_in_bytes - memory.stat[total_cache] |
kubectl top pod |
K8s | memory.usage_in_bytes - memory.stat[total_inactive_file] |
我的serverless平台是目前使用Docker的计算方式,这里的问题在于total_cache是包含了tmpfs的页面的,这一部分页面只能被swapout,而平台上是禁用了swap,因此表面看上去还有大量内存,实际上已经快oom了,只有基于LRU的total_inactive_file,才是准确的能释放的内存量
举个实际的例子:
1 | ~ cat /sys/fs/cgroup/memory/LEAFGZ/876f129e-bb7d-4e00-9a10-d534d7729450_10/memory.limit_in_bytes |
根据Docker的算法,计算的数值是(13526450176 - 12960833536)/1024/1024/1024 = 0.526
根据K8s的算法,计算的数值是(13526450176 - 34922496)/1024/1024/1024 = 12.564
而这个进程的文件系统namespace的/tmp下正好12G
1 | ~ du -sh /tmp/ |
显然这种情况下K8s的算法更合理
参考资料
linux内核中的各种内存分配函数:kmalloc、vmalloc、slab、__get_free_pages、mempoll_alloc
-
简称LKD,从入门开始,介绍了诸如进程管理、系统调用、中断和中断处理程序、内核同步、时间管理、内存管理、地址空间、调试技术等方面,内容比较浅显易懂,个人认为是内核新人首先必读的书籍。
基于2.6.34,是三本书里面最新的
-
简称ULK,相比于LKD的内容不够深入、覆盖面不广,ULK要深入全面得多。
基于2.6.11
《深入理解Linux虚拟内存管理》
简称LVMM,是一本介绍Linux虚拟内存管理机制的书。如果你希望深入的研究Linux的内存管理子系统,仔细的研读这本书无疑是最好的选择。
基于2.6.0,太旧了,很多部分已经完全对不上了,例如页面回收算法一章,很多函数和数据结构已经完全改掉了,只能看个大概流程
-
是区分mmap的读写和bufferIO的读写的脏页追踪情况的
-
同上
-
本文介绍了常用的内存查询命令和内存相关指标的含义。
附录
linux 2.6.39的内核编译和代码阅读
根据测试,以下操作到3.19都可用
编译
根据https://stackoverflow.com/questions/33550251/fatal-error-linux-compiler-gcc5-h-no-such-file-or-directory-during-bitbake
As you're fetching the kernel directly from Linus' tree, the 3.16 version does not support building with gcc5.
If you change to instead fetch from
git://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git, i.e. the stable tree, and change to v3.16.7
linux 3.0的部分版本开始,就不能使用gcc5编译了,因此2.6.39只能使用ubuntu14.04编译
整一个Dockerfile如下
1 | #如果这个镜像站不可用了,那么在https://www.coderjia.cn/archives/dba3f94c-a021-468a-8ac6-e840f85867ea找一个可用的 |
然后
1 | ~ docker build -t my-ssh-image . |
接着就可以用vscode登陆进去编译了,然后clone项目
1 | ~ git clone https://github.com/torvalds/linux.git && cd linux && git checkout v2.6.39 |
准备完毕,正式编译
1 | ~ make menuconfig |
弹出可视界面

选择这里

然后就可以退出了

接着编译
1 | bear -- make -j |
阅读
经过尝试,ubuntu 14.04下没办法安装任何一个clangd用于vscode阅读代码
但是可以把整个编译好的linux项目拷贝到可用clangd的机器上,虽然vscode显示clangd在疯狂报错,但是跳转等基本功能没啥问题
如果使用ubuntu16.04编译3.19的话,就没这个问题,vscode是支持的
-
2026-07-01
这篇记录一次排障过程:从业务进程退出卡住、线程栈落到
__lock_page开始,先用函数级 SystemTap 看这个 page lock 热点像哪类问题,再用字段级 SystemTap 往 cached readdir 里面看,最后回到 FUSE 源码解释为什么会卡住。太长不看版
这个案例的表面现象是:业务进程退出时卡住,相关线程迟迟不能被完整回收。继续看线程状态和栈,卡点落在 Nydus/FUSE 的目录读取路径上。
可以先用一个图书馆类比理解:
nydusd像原始馆藏,目录项最初从这里来;第一次没有缓存时,FUSE 像抄写员,从nydusd拿目录项,同时写进内核里的公共抄本;后续使用缓存时,FUSE 像读抄本的人,拿着自己的书签从公共抄本里继续读。正常情况下,第一次读目录时,FUSE 从
nydusd拿目录项,同时把目录项写进公共抄本;后续再读时,reader 拿着自己的书签从这份抄本里继续读,读完一条记录,书签就往前挪。